
An Image is Worth 16x16 Words, What is a Video Worth?
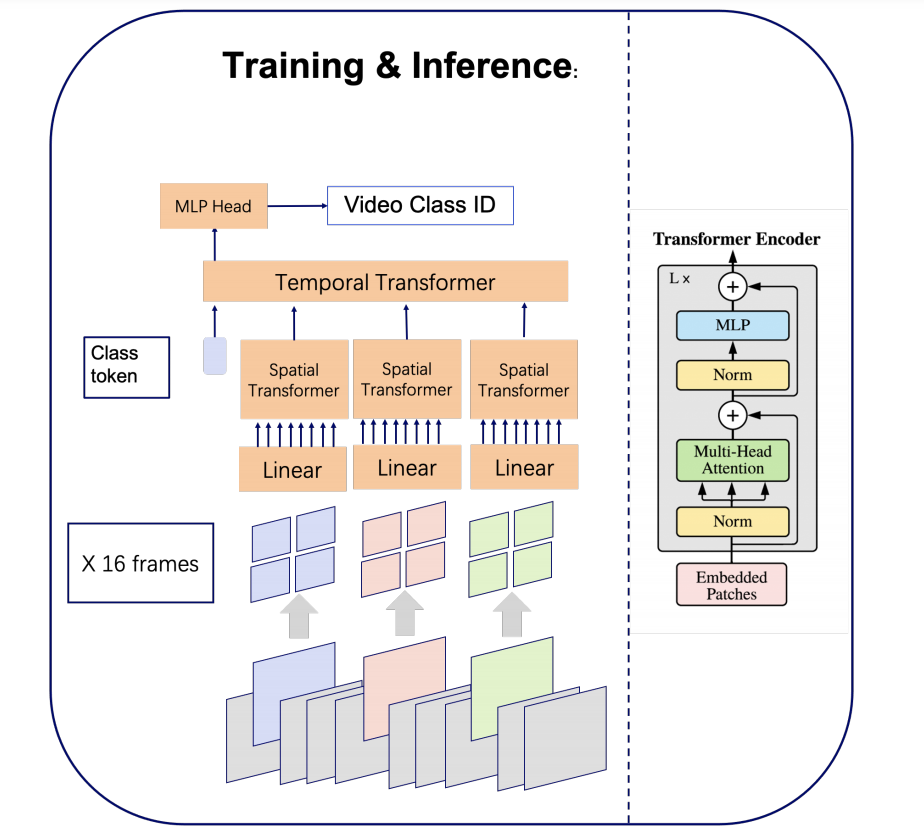
Leading methods in the domain of action recognition try to distill information from both the spatial and temporal dimensions of an input video. Methods that reach State of the Art (SotA) accuracy, usually make use of 3D convolution layers as a way to abstract the temporal information from video frames. The use of such convolutions requires sampling short clips from the input video, where each clip is a collection of closely sampled frames. Since each short clip covers a small fraction of an input video, multiple clips are sampled at inference in order to cover the whole temporal length of the video. This leads to increased computational load and is impractical for real-world applications. We address the computational bottleneck by significantly reducing the number of frames required for inference. Our approach relies on a temporal transformer that applies global attention over video frames, and thus better exploits the salient information in each frame. Therefore our approach is very input efficient, and can achieve SotA results (on Kinetics dataset) with a fraction of the data (frames per video), computation and latency. Specifically on Kinetics-400, we reach $80.5$ top-1 accuracy with $\times 30$ less frames per video, and $\times 40$ faster inference than the current leading method. Code is available at: https://github.com/Alibaba-MIIL/STAM
PDF AbstractCode



Datasets
 UCF101
UCF101
 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
Results from the Paper
 Ranked #23 on
Action Recognition
on UCF101
(using extra training data)
Ranked #23 on
Action Recognition
on UCF101
(using extra training data)
