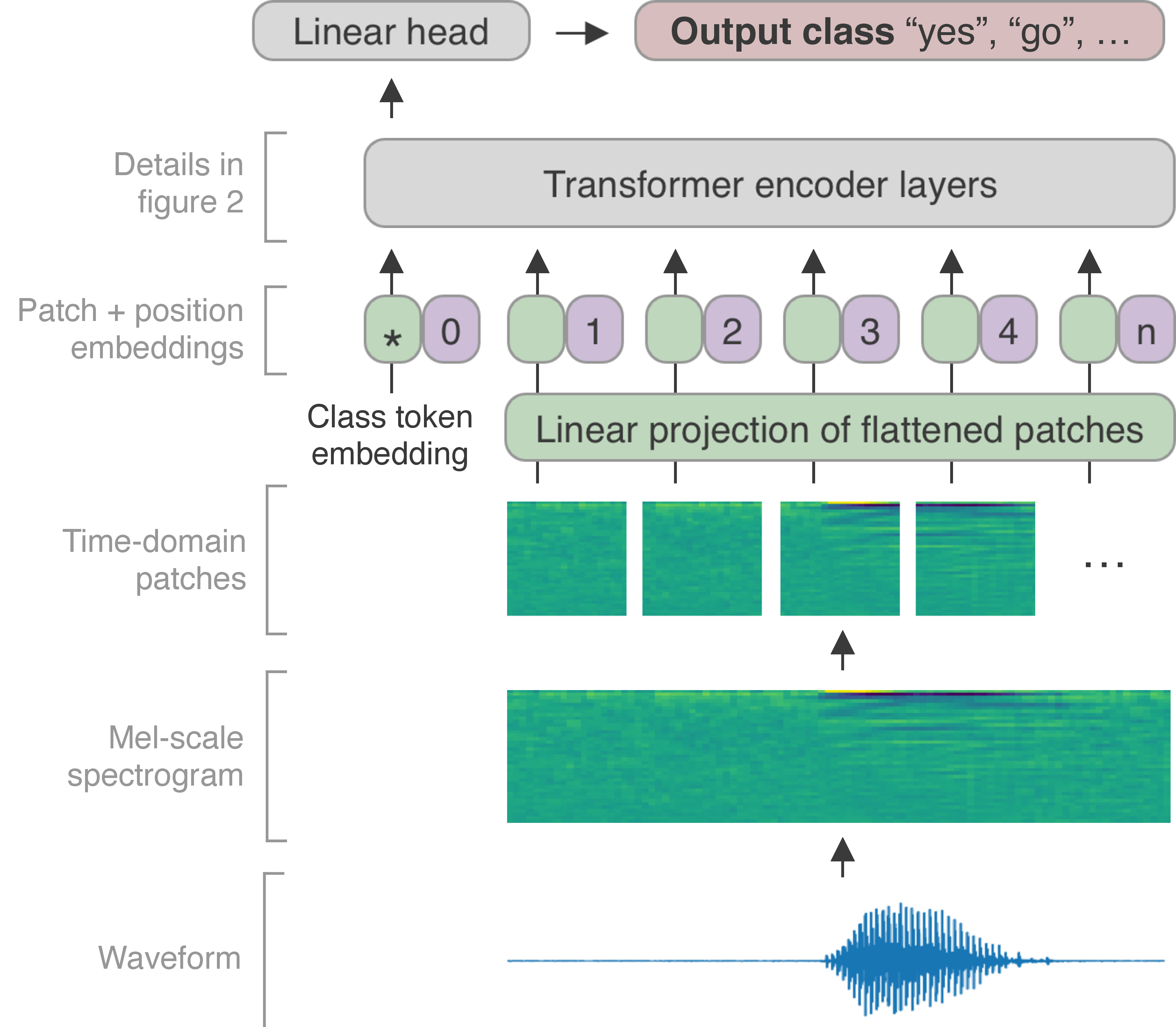

Keyword Transformer: A Self-Attention Model for Keyword Spotting
The Transformer architecture has been successful across many domains, including natural language processing, computer vision and speech recognition. In keyword spotting, self-attention has primarily been used on top of convolutional or recurrent encoders. We investigate a range of ways to adapt the Transformer architecture to keyword spotting and introduce the Keyword Transformer (KWT), a fully self-attentional architecture that exceeds state-of-the-art performance across multiple tasks without any pre-training or additional data. Surprisingly, this simple architecture outperforms more complex models that mix convolutional, recurrent and attentive layers. KWT can be used as a drop-in replacement for these models, setting two new benchmark records on the Google Speech Commands dataset with 98.6% and 97.7% accuracy on the 12 and 35-command tasks respectively.
PDF AbstractCode

 Colab
Colab



Datasets
 Speech Commands
Speech Commands
Results from the Paper
 Ranked #5 on
Keyword Spotting
on Google Speech Commands
(using extra training data)
Ranked #5 on
Keyword Spotting
on Google Speech Commands
(using extra training data)
