Text to Image Generation with Semantic-Spatial Aware GAN
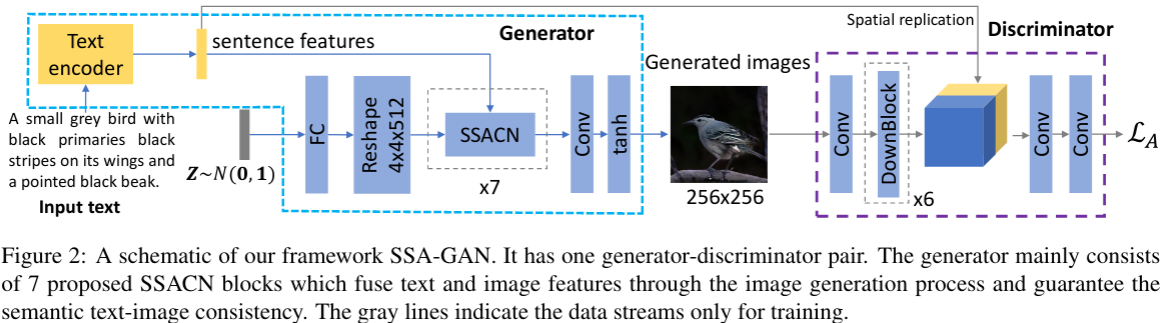
Text-to-image synthesis (T2I) aims to generate photo-realistic images which are semantically consistent with the text descriptions. Existing methods are usually built upon conditional generative adversarial networks (GANs) and initialize an image from noise with sentence embedding, and then refine the features with fine-grained word embedding iteratively. A close inspection of their generated images reveals a major limitation: even though the generated image holistically matches the description, individual image regions or parts of somethings are often not recognizable or consistent with words in the sentence, e.g. "a white crown". To address this problem, we propose a novel framework Semantic-Spatial Aware GAN for synthesizing images from input text. Concretely, we introduce a simple and effective Semantic-Spatial Aware block, which (1) learns semantic-adaptive transformation conditioned on text to effectively fuse text features and image features, and (2) learns a semantic mask in a weakly-supervised way that depends on the current text-image fusion process in order to guide the transformation spatially. Experiments on the challenging COCO and CUB bird datasets demonstrate the advantage of our method over the recent state-of-the-art approaches, regarding both visual fidelity and alignment with input text description.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



 MS COCO
MS COCO
 CUB-200-2011
CUB-200-2011
