Search Results for author:
Found 185 papers, 76 papers with code
RBF-Softmax: Learning Deep Representative Prototypes with Radial Basis Function Softmax
To address this problem, this paper introduces a novel Radial Basis Function (RBF) distances to replace the commonly used inner products in the softmax loss function, such that it can adaptively assign losses to regularize the intra-class and inter-class distances by reshaping the relative differences, and thus creating more representative prototypes of classes to improve optimization.
Efficient Preference-based Reinforcement Learning via Aligned Experience Estimation
To boost the learning loop, we propose SEER, an efficient PbRL method that integrates label smoothing and policy regularization techniques.
A Vlogger-augmented Graph Neural Network Model for Micro-video Recommendation
Moreover, we conduct cross-view contrastive learning to keep the consistency between node embeddings from the two different views.
CoSLight: Co-optimizing Collaborator Selection and Decision-making to Enhance Traffic Signal Control
Effective multi-intersection collaboration is pivotal for reinforcement-learning-based traffic signal control to alleviate congestion.
What Makes Good Few-shot Examples for Vision-Language Models?
Despite the notable advancements achieved by leveraging pre-trained vision-language (VL) models through few-shot tuning for downstream tasks, our detailed empirical study highlights a significant dependence of few-shot learning outcomes on the careful selection of training examples - a facet that has been previously overlooked in research.
SQL-to-Schema Enhances Schema Linking in Text-to-SQL
Consequently, there is a critical need to filter out unnecessary tables and columns, directing the language models attention to relevant tables and columns with schema-linking, to reduce errors during SQL generation.

Resilient control of networked switched systems subject to deception attack and DoS attack
In this paper, the resilient control for switched systems in the presence of deception attack and denial-of-service (DoS) attack is addressed.
Estimating Noisy Class Posterior with Part-level Labels for Noisy Label Learning
Utilizing this framework with part-level labels, we can learn the noisy class posteriors more precisely by guiding the model to integrate information from various parts, ultimately improving the classification performance.
Causal Evaluation of Language Models
Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning.


X-Light: Cross-City Traffic Signal Control Using Transformer on Transformer as Meta Multi-Agent Reinforcement Learner
The effectiveness of traffic light control has been significantly improved by current reinforcement learning-based approaches via better cooperation among multiple traffic lights.
Balancing Speciality and Versatility: a Coarse to Fine Framework for Supervised Fine-tuning Large Language Model
In an overall evaluation of both speciality and versatility, CoFiTune consistently outperforms baseline methods across diverse tasks and model scales.

Sparse Global Matching for Video Frame Interpolation with Large Motion
Large motion poses a critical challenge in Video Frame Interpolation (VFI) task.
Xiwu: A Basis Flexible and Learnable LLM for High Energy Physics
To address this challenge, a sophisticated large language model system named as Xiwu has been developed, allowing you switch between the most advanced foundation models and quickly teach the model domain knowledge.

SocialGenPod: Privacy-Friendly Generative AI Social Web Applications with Decentralised Personal Data Stores
Unlike centralised Web and data architectures that keep user data tied to application and service providers, we show how one can use Solid -- a decentralised Web specification -- to decouple user data from generative AI applications.
PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
Then, in the first stage, question-SQL pairs are retrieved as few-shot demonstrations, prompting the LLM to generate a preliminary SQL (PreSQL).
 Ranked #1 on
Text-To-SQL
on spider
Ranked #1 on
Text-To-SQL
on spider
DragAnything: Motion Control for Anything using Entity Representation
We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video generation.

Perennial Semantic Data Terms of Use for Decentralized Web
We believe this work demonstrates a practicality of a perennial DToU language and the potential of a paradigm shift to how users interact with data and applications in a decentralized Web, offering both improved privacy and usability.
Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation
Then we formulate five evaluation tasks to comprehensively assess the performance of diverse methods across various LLMs throughout the Text-to-SQL process. Our study highlights the performance disparities among LLMs and proposes optimal in-context learning solutions tailored to each task.
Consistency Matters: Explore LLMs Consistency From a Black-Box Perspective
The solution to this problem is often time-consuming and labor-intensive, and there is also an additional cost of secondary deployment, resulting in economic and time losses.
Non-Neighbors Also Matter to Kriging: A New Contrastive-Prototypical Learning
As a pre-trained paradigm, we conduct the Kriging task from a new perspective of representation: we aim to first learn robust and general representations and then recover attributes from representations.

Spatial-Temporal Large Language Model for Traffic Prediction
In this paper, we propose a Spatial-Temporal Large Language Model (ST-LLM) for traffic prediction.
Towards A Better Metric for Text-to-Video Generation
Experiments on the TVGE dataset demonstrate the superiority of the proposed T2VScore on offering a better metric for text-to-video generation.
PDiT: Interleaving Perception and Decision-making Transformers for Deep Reinforcement Learning
Designing better deep networks and better reinforcement learning (RL) algorithms are both important for deep RL.
Conditional Variational Autoencoder for Sign Language Translation with Cross-Modal Alignment
The first KL divergence optimizes the conditional variational autoencoder and regularizes the encoder outputs, while the second KL divergence performs a self-distillation from the posterior path to the prior path, ensuring the consistency of decoder outputs.

DuaLight: Enhancing Traffic Signal Control by Leveraging Scenario-Specific and Scenario-Shared Knowledge
Furthermore, we implement a scenario-shared Co-Train module to facilitate the learning of generalizable dynamics information across different scenarios.
VisionTraj: A Noise-Robust Trajectory Recovery Framework based on Large-scale Camera Network
Trajectory recovery based on the snapshots from the city-wide multi-camera network facilitates urban mobility sensing and driveway optimization.


X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model
To enhance the guidance ability of X-Adapter, we employ a null-text training strategy for the upgraded model.
Hulk: A Universal Knowledge Translator for Human-Centric Tasks
Human-centric perception tasks, e. g., pedestrian detection, skeleton-based action recognition, and pose estimation, have wide industrial applications, such as metaverse and sports analysis.
 Ranked #1 on
Pedestrian Image Caption
on CUHK-PEDES
Ranked #1 on
Pedestrian Image Caption
on CUHK-PEDES


VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape.
Controlling Large Language Model-based Agents for Large-Scale Decision-Making: An Actor-Critic Approach
The remarkable progress in Large Language Models (LLMs) opens up new avenues for addressing planning and decision-making problems in Multi-Agent Systems (MAS).
TPTU-v2: Boosting Task Planning and Tool Usage of Large Language Model-based Agents in Real-world Systems
Large Language Models (LLMs) have demonstrated proficiency in addressing tasks that necessitate a combination of task planning and the usage of external tools that require a blend of task planning and the utilization of external tools, such as APIs.
To be or not to be? an exploration of continuously controllable prompt engineering
In response, we introduce ControlPE (Continuously Controllable Prompt Engineering).

What Large Language Models Bring to Text-rich VQA?
This pipeline achieved superior performance compared to the majority of existing Multimodal Large Language Models (MLLM) on four text-rich VQA datasets.

KITS: Inductive Spatio-Temporal Kriging with Increment Training Strategy
To address this issue, we first present a novel Increment training strategy: instead of masking nodes (and reconstructing them), we add virtual nodes into the training graph so as to mitigate the graph gap issue naturally.
A Critical Perceptual Pre-trained Model for Complex Trajectory Recovery
Then, we propose a Multi-view Graph and Complexity Aware Transformer (MGCAT) model to encode these semantics in trajectory pre-training from two aspects: 1) adaptively aggregate the multi-view graph features considering trajectory pattern, and 2) higher attention to critical nodes in a complex trajectory.
Decentralised, Scalable and Privacy-Preserving Synthetic Data Generation
Synthetic data is emerging as a promising way to harness the value of data, while reducing privacy risks.
Reboost Large Language Model-based Text-to-SQL, Text-to-Python, and Text-to-Function -- with Real Applications in Traffic Domain
Our experiments with Large Language Models (LLMs) illustrate the significant performance improvement on the business dataset and prove the substantial potential of our method.
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
To overcome this, we propose to introduce the dynamic Neural Radiance Fields (NeRF) as the innovative video representation, where the editing can be performed in the 3D spaces and propagated to the entire video via the deformation field.


MeanAP-Guided Reinforced Active Learning for Object Detection
Active learning presents a promising avenue for training high-performance models with minimal labeled data, achieved by judiciously selecting the most informative instances to label and incorporating them into the task learner.
MotionDirector: Motion Customization of Text-to-Video Diffusion Models
Given a set of video clips of the same motion concept, the task of Motion Customization is to adapt existing text-to-video diffusion models to generate videos with this motion.
InstructDET: Diversifying Referring Object Detection with Generalized Instructions
In order to encompass common detection expressions, we involve emerging vision-language model (VLM) and large language model (LLM) to generate instructions guided by text prompts and object bbxs, as the generalizations of foundation models are effective to produce human-like expressions (e. g., describing object property, category, and relationship).
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
In this paper, we are the first to propose a hybrid model, dubbed as Show-1, which marries pixel-based and latent-based VDMs for text-to-video generation.
 Ranked #2 on
Text-to-Video Generation
on EvalCrafter Text-to-Video (ECTV) Dataset
(using extra training data)
Ranked #2 on
Text-to-Video Generation
on EvalCrafter Text-to-Video (ECTV) Dataset
(using extra training data)
t-SOT FNT: Streaming Multi-talker ASR with Text-only Domain Adaptation Capability
Token-level serialized output training (t-SOT) was recently proposed to address the challenge of streaming multi-talker automatic speech recognition (ASR).
 Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+3
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+3
Hybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
Attention-based encoder-decoder (AED) speech recognition model has been widely successful in recent years.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments.
Link-Context Learning for Multimodal LLMs
The ability to learn from context with novel concepts, and deliver appropriate responses are essential in human conversations.
DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation.

Zero-shot Text-driven Physically Interpretable Face Editing
Our method can also be flexibly extended to real-time video face editing.
TPTU: Large Language Model-based AI Agents for Task Planning and Tool Usage
With recent advancements in natural language processing, Large Language Models (LLMs) have emerged as powerful tools for various real-world applications.
Relation-Aware Distribution Representation Network for Person Clustering with Multiple Modalities
The distribution representation of a clue is a vector consisting of the relation between this clue and all other clues from all modalities, thus being modality agnostic and good for person clustering.
Described Object Detection: Liberating Object Detection with Flexible Expressions
In this paper, we advance them to a more practical setting called Described Object Detection (DOD) by expanding category names to flexible language expressions for OVD and overcoming the limitation of REC only grounding the pre-existing object.

Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Referential dialogue is a superset of various vision-language (VL) tasks.
 Ranked #10 on
Visual Question Answering
on ViP-Bench
Ranked #10 on
Visual Question Answering
on ViP-Bench


Interaction-Aware Planning With Deep Inverse Reinforcement Learning for Human-Like Autonomous Driving in Merge Scenarios
To consider the interaction factor, the reward function for planning is utilized to evaluate the joint trajectories of the autonomous driving vehicle (ADV) and traffic vehicles.

Patch-Level Contrasting without Patch Correspondence for Accurate and Dense Contrastive Representation Learning
On classification tasks, for ViT-S, ADCLR achieves 77. 5% top-1 accuracy on ImageNet with linear probing, outperforming our baseline (DINO) without our devised techniques as plug-in, by 0. 5%.

Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis
By fine-tuning CLIP on HPD v2, we obtain Human Preference Score v2 (HPS v2), a scoring model that can more accurately predict human preferences on generated images.

Instruct-ReID: A Multi-purpose Person Re-identification Task with Instructions
This paper strives to resolve this problem by proposing a new instruct-ReID task that requires the model to retrieve images according to the given image or language instructions.

Dynamic Causal Graph Convolutional Network for Traffic Prediction
In this work, we propose a novel approach for traffic prediction that embeds time-varying dynamic Bayesian network to capture the fine spatiotemporal topology of traffic data.
 Ranked #13 on
Traffic Prediction
on METR-LA
Ranked #13 on
Traffic Prediction
on METR-LA

Correlated Time Series Self-Supervised Representation Learning via Spatiotemporal Bootstrapping
We evaluated the effectiveness and flexibility of our representation learning framework on correlated time series forecasting and cold-start transferring the forecasting model to new instances with limited data.
Correlated Time Series Forecasting
 Representation Learning
+1
Representation Learning
+1
MM-DAG: Multi-task DAG Learning for Multi-modal Data -- with Application for Traffic Congestion Analysis
This encourages the multi-task design: with each DAG as a task, the MM-DAG tries to learn the multiple DAGs jointly so that their consensus and consistency are maximized.
Balancing Logit Variation for Long-tailed Semantic Segmentation
In this way, we manage to close the gap between the feature areas of different categories, resulting in a more balanced representation.

Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models
Public large-scale text-to-image diffusion models, such as Stable Diffusion, have gained significant attention from the community.
Deeply Coupled Cross-Modal Prompt Learning
Recent advancements in multimodal foundation models (e. g., CLIP) have excelled in zero-shot generalization.

ZeroPose: CAD-Model-based Zero-Shot Pose Estimation
In this paper, we present a CAD model-based zero-shot pose estimation pipeline called ZeroPose.
Advancing Referring Expression Segmentation Beyond Single Image
To overcome this limitation, we propose a more realistic and general setting, named Group-wise Referring Expression Segmentation (GRES), which expands RES to a collection of related images, allowing the described objects to be present in a subset of input images.

Stackelberg Decision Transformer for Asynchronous Action Coordination in Multi-Agent Systems
Our research contributes to the development of an effective and adaptable asynchronous action coordination method that can be widely applied to various task types and environmental configurations in MAS.
Human Preference Score: Better Aligning Text-to-Image Models with Human Preference
To address this issue, we collect a dataset of human choices on generated images from the Stable Foundation Discord channel.
WM-MoE: Weather-aware Multi-scale Mixture-of-Experts for Blind Adverse Weather Removal
To this end, we propose a method called Weather-aware Multi-scale MoE (WM-MoE) based on Transformer for blind weather removal.

Explore the Power of Synthetic Data on Few-shot Object Detection
To construct a representative synthetic training dataset, we maximize the diversity of the selected images via a sample-based and cluster-based method.

CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching
To overcome these obstacles, we propose CORA, a DETR-style framework that adapts CLIP for Open-vocabulary detection by Region prompting and Anchor pre-matching.
 Ranked #6 on
Open Vocabulary Object Detection
on MSCOCO
(using extra training data)
Ranked #6 on
Open Vocabulary Object Detection
on MSCOCO
(using extra training data)
SpikeCV: Open a Continuous Computer Vision Era
SpikeCV focuses on encapsulation for spike data, standardization for dataset interfaces, modularization for vision tasks, and real-time applications for challenging scenes.
SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers
To this end, we propose SeqCo-DETR, a novel Sequence Consistency-based self-supervised method for object DEtection with TRansformers.
HumanBench: Towards General Human-centric Perception with Projector Assisted Pretraining
Specifically, we propose a \textbf{HumanBench} based on existing datasets to comprehensively evaluate on the common ground the generalization abilities of different pretraining methods on 19 datasets from 6 diverse downstream tasks, including person ReID, pose estimation, human parsing, pedestrian attribute recognition, pedestrian detection, and crowd counting.
 Ranked #1 on
Pedestrian Attribute Recognition
on PA-100K
(using extra training data)
Ranked #1 on
Pedestrian Attribute Recognition
on PA-100K
(using extra training data)
UniHCP: A Unified Model for Human-Centric Perceptions
When adapted to a specific task, UniHCP achieves new SOTAs on a wide range of human-centric tasks, e. g., 69. 8 mIoU on CIHP for human parsing, 86. 18 mA on PA-100K for attribute prediction, 90. 3 mAP on Market1501 for ReID, and 85. 8 JI on CrowdHuman for pedestrian detection, performing better than specialized models tailored for each task.
 Ranked #1 on
Pose Estimation
on MS-COCO
Ranked #1 on
Pose Estimation
on MS-COCO
Zero-Shot Text-to-Parameter Translation for Game Character Auto-Creation
In our method, taking the power of large-scale pre-trained multi-modal CLIP and neural rendering, T2P searches both continuous facial parameters and discrete facial parameters in a unified framework.
An Effective Crop-Paste Pipeline for Few-shot Object Detection
Specifically, we first discover the base images which contain the FP of novel categories and select a certain amount of samples from them for the base and novel categories balance.

Efficient Masked Autoencoders with Self-Consistency
However, its high random mask ratio would result in two serious problems: 1) the data are not efficiently exploited, which brings inefficient pre-training (\eg, 1600 epochs for MAE $vs.$ 300 epochs for the supervised), and 2) the high uncertainty and inconsistency of the pre-trained model, \ie, the prediction of the same patch may be inconsistent under different mask rounds.
Saliency Guided Contrastive Learning on Scene Images
Despite being feasible, recent works largely overlooked discovering the most discriminative regions for contrastive learning to object representations in scene images.
Explore the Power of Dropout on Few-shot Learning
The generalization power of the pre-trained model is the key for few-shot deep learning.

SparseMAE: Sparse Training Meets Masked Autoencoders
In this paper, we aim to reduce model complexity from large vision transformers pretrained by MAE with assistant of sparse training.
Transformer in Transformer as Backbone for Deep Reinforcement Learning
Recent methods combine the Transformer with these modules for better performance.
Fast and accurate factorized neural transducer for text adaption of end-to-end speech recognition models
Neural transducer is now the most popular end-to-end model for speech recognition, due to its naturally streaming ability.
Exploring Stochastic Autoregressive Image Modeling for Visual Representation
By introducing stochastic prediction and the parallel encoder-decoder, SAIM significantly improve the performance of autoregressive image modeling.
PUnifiedNER: A Prompting-based Unified NER System for Diverse Datasets
In this work, we present a ``versatile'' model -- the Prompting-based Unified NER system (PUnifiedNER) -- that works with data from different domains and can recognise up to 37 entity types simultaneously, and theoretically it could be as many as possible.
MIAD: A Maintenance Inspection Dataset for Unsupervised Anomaly Detection
However, existing datasets for unsupervised anomaly detection are biased towards manufacturing inspection, not considering maintenance inspection which is usually conducted under outdoor uncontrolled environment such as varying camera viewpoints, messy background and degradation of object surface after long-term working.
LongFNT: Long-form Speech Recognition with Factorized Neural Transducer
This motivates us to leverage the factorized neural transducer structure, containing a real language model, the vocabulary predictor.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+3
Geo6D: Geometric Constraints Learning for 6D Pose Estimation
Numerous 6D pose estimation methods have been proposed that employ end-to-end regression to directly estimate the target pose parameters.

A Unified Framework with Meta-dropout for Few-shot Learning
Conventional training of deep neural networks usually requires a substantial amount of data with expensive human annotations.
SDA: Simple Discrete Augmentation for Contrastive Sentence Representation Learning
Contrastive learning has recently achieved compelling performance in unsupervised sentence representation.
What Makes Pre-trained Language Models Better Zero-shot Learners?
Current methods for prompt learning in zeroshot scenarios widely rely on a development set with sufficient human-annotated data to select the best-performing prompt template a posteriori.
Obj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks
Obj2Seq is able to flexibly determine input categories to satisfy customized requirements, and be easily extended to different visual tasks.
Learning from Future: A Novel Self-Training Framework for Semantic Segmentation
Self-training has shown great potential in semi-supervised learning.

Jointly Contrastive Representation Learning on Road Network and Trajectory
Unlike the existing cross-scale contrastive learning methods on graphs that only contrast a graph and its belonging nodes, the contrast between road segment and trajectory is elaborately tailored via novel positive sampling and adaptive weighting strategies.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Uni6D is the first 6D pose estimation approach to employ a unified backbone network to extract features from both RGB and depth images.
Counterfactual Intervention Feature Transfer for Visible-Infrared Person Re-identification
But we find existing graph-based methods in the visible-infrared person re-identification task (VI-ReID) suffer from bad generalization because of two issues: 1) train-test modality balance gap, which is a property of VI-ReID task.
Auto-Encoding Adversarial Imitation Learning
In this work, we propose Auto-Encoding Adversarial Imitation Learning (AEAIL), a robust and scalable AIL framework.
Domain Invariant Masked Autoencoders for Self-supervised Learning from Multi-domains
While recent self-supervised learning methods have achieved good performances with evaluation set on the same domain as the training set, they will have an undesirable performance decrease when tested on a different domain.
DOTIN: Dropping Task-Irrelevant Nodes for GNNs
Scalability is an important consideration for deep graph neural networks.

Uni6D: A Unified CNN Framework without Projection Breakdown for 6D Pose Estimation
They use a 2D CNN for RGB images and a per-pixel point cloud network for depth data, as well as a fusion network for feature fusion.
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
Furthermore, our method can also exploit single-centric-object dataset such as ImageNet and outperforms BYOL by 2. 5% with the same pre-training epochs in linear probing, and surpass current self-supervised object detection methods on COCO dataset, demonstrating its universality and potential.

Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
A common practice is to select the highly confident predictions as the pseudo ground-truth, but it leads to a problem that most pixels may be left unused due to their unreliability.

Align Representations With Base: A New Approach to Self-Supervised Learning
Existing symmetric contrastive learning methods suffer from collapses (complete and dimensional) or quadratic complexity of objectives.
Maximum Entropy Population-Based Training for Zero-Shot Human-AI Coordination
We study the problem of training a Reinforcement Learning (RL) agent that is collaborative with humans without using any human data.
Feature Erasing and Diffusion Network for Occluded Person Re-Identification
With the guidance of the occlusion scores from OEM, the feature diffusion process is mainly conducted on visible body parts, which guarantees the quality of the synthesized NTP characteristics.
 Ranked #1 on
Person Re-Identification
on Occluded REID
(Rank-1 metric)
Ranked #1 on
Person Re-Identification
on Occluded REID
(Rank-1 metric)
Revisiting the Transferability of Supervised Pretraining: an MLP Perspective
The pretrain-finetune paradigm is a classical pipeline in visual learning.
FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows
However, current methods can not effectively map image features to a tractable base distribution and ignore the relationship between local and global features which are important to identify anomalies.
 Ranked #20 on
Anomaly Detection
on MVTec AD
Ranked #20 on
Anomaly Detection
on MVTec AD
Unsupervised Anomaly Detection
Weakly Supervised Defect Detection
Boundary Distribution Estimation for Precise Object Detection
In the field of state-of-the-art object detection, the task of object localization is typically accomplished through a dedicated subnet that emphasizes bounding box regression.
Focus Your Distribution: Coarse-to-Fine Non-Contrastive Learning for Anomaly Detection and Localization
To facilitate the learning with only normal images, we propose a new pretext task called non-contrastive learning for the fine alignment stage.
Ranked #49 on
Anomaly Detection
on MVTec AD
Optical Flow Estimation for Spiking Camera
Further, for training SCFlow, we synthesize two sets of optical flow data for the spiking camera, SPIkingly Flying Things and Photo-realistic High-speed Motion, denoted as SPIFT and PHM respectively, corresponding to random high-speed and well-designed scenes.

Dr.Aid: Supporting Data-governance Rule Compliance for Decentralized Collaboration in an Automated Way
It depends on federations sharing data that often have governance rules or external regulations restricting their use.
MDFL: A UNIFIED FRAMEWORK WITH META-DROPOUT FOR FEW-SHOT LEARNING
Conventional training of deep neural networks usually requires a substantial amount of data with expensive human annotations.
Improving the Transferability of Supervised Pretraining with an MLP Projector
The pretrain-finetune paradigm is a classical pipeline in visual learning.
Zero-CL: Instance and Feature decorrelation for negative-free symmetric contrastive learning
The proposed two methods (FCL, ICL) can be combined synthetically, called Zero-CL, where ``Zero'' means negative samples are \textbf{zero} relevant, which allows Zero-CL to completely discard negative pairs i. e., with \textbf{zero} negative samples.
Auto-Encoding Inverse Reinforcement Learning
Reinforcement learning (RL) provides a powerful framework for decision-making, but its application in practice often requires a carefully designed reward function.
Multi-Source Video Domain Adaptation with Temporal Attentive Moment Alignment
Multi-Source Domain Adaptation (MSDA) is a more practical domain adaptation scenario in real-world scenarios.
Spatio-Temporal Recurrent Networks for Event-Based Optical Flow Estimation
Recently, many deep learning methods have shown great success in providing promising solutions to many event-based problems, such as optical flow estimation.

An Automated Framework for Supporting Data-Governance Rule Compliance in Decentralized MIMO Contexts
We propose Dr. Aid, a logic-based AI framework for automated compliance checking of data governance rules over data-flow graphs.
MST: Masked Self-Supervised Transformer for Visual Representation
More importantly, the masked tokens together with the remaining tokens are further recovered by a global image decoder, which preserves the spatial information of the image and is more friendly to the downstream dense prediction tasks.
Improving Facial Attribute Recognition by Group and Graph Learning
For the spatial correlation, we aggregate attributes with spatial similarity into a part-based group and then introduce a Group Attention Learning to generate the group attention and the part-based group feature.
Multiple Domain Experts Collaborative Learning: Multi-Source Domain Generalization For Person Re-Identification
In UDCL, a universal expert supervises the learning of domain experts and continuously gathers knowledge from all domain experts.

Neighbourhood-guided Feature Reconstruction for Occluded Person Re-Identification
Person images captured by surveillance cameras are often occluded by various obstacles, which lead to defective feature representation and harm person re-identification (Re-ID) performance.
Self-distillation with Batch Knowledge Ensembling Improves ImageNet Classification
In this way, our BAKE framework achieves online knowledge ensembling across multiple samples with only a single network.


On Addressing Practical Challenges for RNN-Transducer
The first challenge is solved with a splicing data method which concatenates the speech segments extracted from the source domain data.

Memory Enhanced Embedding Learning for Cross-Modal Video-Text Retrieval
The cross-modal memory module is employed to record the instance embeddings of all the datasets for global negative mining.
Mutual Information State Intrinsic Control
Reinforcement learning has been shown to be highly successful at many challenging tasks.
Progressive Correspondence Pruning by Consensus Learning
Correspondence selection aims to correctly select the consistent matches (inliers) from an initial set of putative correspondences.

Internal Language Model Estimation for Domain-Adaptive End-to-End Speech Recognition
The external language models (LM) integration remains a challenging task for end-to-end (E2E) automatic speech recognition (ASR) which has no clear division between acoustic and language models.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+3
The Vulnerability of the Neural Networks Against Adversarial Examples in Deep Learning Algorithms
Based on current security threats faced by deep learning, this paper introduces the problem of adversarial examples in deep learning, sorts out the existing attack and defense methods of the black box and white box, and classifies them.
Enhancing and Learning Denoiser without Clean Reference
Recent studies on learning-based image denoising have achieved promising performance on various noise reduction tasks.

Transfer Learning Approaches for Streaming End-to-End Speech Recognition System
Transfer learning (TL) is widely used in conventional hybrid automatic speech recognition (ASR) system, to transfer the knowledge from source to target language.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+2
Woodpecker-DL: Accelerating Deep Neural Networks via Hardware-Aware Multifaceted Optimizations
Accelerating deep model training and inference is crucial in practice.
Deep Reinforcement Learning Based Mobile Edge Computing for Intelligent Internet of Things
In particular, the system cost of latency and energy consumption can be reduced significantly by the proposed deep reinforcement learning based algorithm.
Developing RNN-T Models Surpassing High-Performance Hybrid Models with Customization Capability
Because of its streaming nature, recurrent neural network transducer (RNN-T) is a very promising end-to-end (E2E) model that may replace the popular hybrid model for automatic speech recognition.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+1
Deep Multi-task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Multi-task learning is an effective learning strategy for deep-learning-based facial expression recognition tasks.
Facial Expression Recognition
 Facial Expression Recognition (FER)
+2
Facial Expression Recognition (FER)
+2
Learning Individualized Treatment Rules with Estimated Translated Inverse Propensity Score
Randomized controlled trials typically analyze the effectiveness of treatments with the goal of making treatment recommendations for patient subgroups.
Enhancement of a CNN-Based Denoiser Based on Spatial and Spectral Analysis
Since most of the content or energy of natural images resides in the low-frequency spectrum, their transformed coefficients in the frequency domain are highly imbalanced.
Continual Representation Learning for Biometric Identification
With the explosion of digital data in recent years, continuously learning new tasks from a stream of data without forgetting previously acquired knowledge has become increasingly important.

Self-supervising Fine-grained Region Similarities for Large-scale Image Localization
The task of large-scale retrieval-based image localization is to estimate the geographical location of a query image by recognizing its nearest reference images from a city-scale dataset.

Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
To solve these problems, we propose a novel self-paced contrastive learning framework with hybrid memory.
 Ranked #3 on
Unsupervised Domain Adaptation
on Market to MSMT
Ranked #3 on
Unsupervised Domain Adaptation
on Market to MSMT
Bayesian Adversarial Human Motion Synthesis
By explicitly capturing the distribution of the data and parameters, our model has a more compact parameterization compared to GAN-based generative models.

On the Comparison of Popular End-to-End Models for Large Scale Speech Recognition
Among all three E2E models, transformer-AED achieved the best accuracy in both streaming and non-streaming mode.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+2
COCAS: A Large-Scale Clothes Changing Person Dataset for Re-identification
To address the clothes changing person re-id problem, we construct a novel large-scale re-id benchmark named ClOthes ChAnging Person Set (COCAS), which provides multiple images of the same identity with different clothes.
Exploring Pre-training with Alignments for RNN Transducer based End-to-End Speech Recognition
Recently, the recurrent neural network transducer (RNN-T) architecture has become an emerging trend in end-to-end automatic speech recognition research due to its advantages of being capable for online streaming speech recognition.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+2
Stacked Convolutional Deep Encoding Network for Video-Text Retrieval
Existing dominant approaches for cross-modal video-text retrieval task are to learn a joint embedding space to measure the cross-modal similarity.
Learning to Cluster Faces via Confidence and Connectivity Estimation
With the vertex confidence and edge connectivity, we can naturally organize more relevant vertices on the affinity graph and group them into clusters.
High-Accuracy and Low-Latency Speech Recognition with Two-Head Contextual Layer Trajectory LSTM Model
While the community keeps promoting end-to-end models over conventional hybrid models, which usually are long short-term memory (LSTM) models trained with a cross entropy criterion followed by a sequence discriminative training criterion, we argue that such conventional hybrid models can still be significantly improved.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+1
Structured Domain Adaptation with Online Relation Regularization for Unsupervised Person Re-ID
To tackle the challenges, we propose an end-to-end structured domain adaptation framework with an online relation-consistency regularization term.
Ranked #4 on
Unsupervised Domain Adaptation
on Market to MSMT
Mutual Information-based State-Control for Intrinsically Motivated Reinforcement Learning
In reinforcement learning, an agent learns to reach a set of goals by means of an external reward signal.
Towards a computer-interpretable actionable formal model to encode data governance rules
With the needs of science and business, data sharing and re-use has become an intensive activity for various areas.
Bayesian Graph Convolution LSTM for Skeleton Based Action Recognition
Finally, the whole model is extended under the Bayesian framework to a probabilistic model in order to better capture the stochasticity and variation in the data.
 Ranked #91 on
Skeleton Based Action Recognition
on NTU RGB+D
Ranked #91 on
Skeleton Based Action Recognition
on NTU RGB+D
Improving RNN Transducer Modeling for End-to-End Speech Recognition
In this paper, we improve the RNN-T training in two aspects.
Automatic Speech Recognition
Automatic Speech Recognition (ASR)
+2
Self-Supervised State-Control through Intrinsic Mutual Information Rewards
Our results show that the mutual information between the context states and the states of interest can be an effective ingredient for overcoming challenges in robotic manipulation tasks with sparse rewards.

Memory-Based Neighbourhood Embedding for Visual Recognition
Learning discriminative image feature embeddings is of great importance to visual recognition.
Bayesian Hierarchical Dynamic Model for Human Action Recognition
Human action recognition remains as a challenging task partially due to the presence of large variations in the execution of action.
 Ranked #3 on
Skeleton Based Action Recognition
on MSR Action3D
Ranked #3 on
Skeleton Based Action Recognition
on MSR Action3D
Maximum Entropy-Regularized Multi-Goal Reinforcement Learning
This objective encourages the agent to maximize the expected return, as well as to achieve more diverse goals.
P2SGrad: Refined Gradients for Optimizing Deep Face Models
Cosine-based softmax losses significantly improve the performance of deep face recognition networks.

AdaCos: Adaptively Scaling Cosine Logits for Effectively Learning Deep Face Representations
Our results show that training deep neural networks with the AdaCos loss is stable and able to achieve high face recognition accuracy.
 Ranked #6 on
Face Verification
on MegaFace
Ranked #6 on
Face Verification
on MegaFace

Neural Networks for Modeling Source Code Edits
In this work, we instead treat source code as a dynamic object and tackle the problem of modeling the edits that software developers make to source code files.
Curiosity-Driven Experience Prioritization via Density Estimation
In Reinforcement Learning (RL), an agent explores the environment and collects trajectories into the memory buffer for later learning.
Advancing Acoustic-to-Word CTC Model with Attention and Mixed-Units
In particular, we introduce Attention CTC, Self-Attention CTC, Hybrid CTC, and Mixed-unit CTC.
Efficient Dialog Policy Learning via Positive Memory Retention
This paper is concerned with the training of recurrent neural networks as goal-oriented dialog agents using reinforcement learning.
Energy-Based Hindsight Experience Prioritization
We evaluate our Energy-Based Prioritization (EBP) approach on four challenging robotic manipulation tasks in simulation.
Learning Goal-Oriented Visual Dialog via Tempered Policy Gradient
Learning goal-oriented dialogues by means of deep reinforcement learning has recently become a popular research topic.
A Hierarchical Generative Model for Eye Image Synthesis and Eye Gaze Estimation
Through a top-down inference, the HGM can synthesize eye images consistent with the given eye gaze.
Bilateral Ordinal Relevance Multi-Instance Regression for Facial Action Unit Intensity Estimation
The majority of methods directly apply supervised learning techniques to AU intensity estimation while few methods exploit unlabeled samples to improve the performance.
Attention-Aware Compositional Network for Person Re-identification
AACN consists of two main components: Pose-guided Part Attention (PPA) and Attention-aware Feature Composition (AFC).
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
On the SQuAD dataset, our model is 3x to 13x faster in training and 4x to 9x faster in inference, while achieving equivalent accuracy to recurrent models.
 Ranked #27 on
Question Answering
on SQuAD1.1 dev
Ranked #27 on
Question Answering
on SQuAD1.1 dev


Developing Far-Field Speaker System Via Teacher-Student Learning
In this study, we develop the keyword spotting (KWS) and acoustic model (AM) components in a far-field speaker system.

Advancing Acoustic-to-Word CTC Model
However, the word-based CTC model suffers from the out-of-vocabulary (OOV) issue as it can only model limited number of words in the output layer and maps all the remaining words into an OOV output node.
Advancing Connectionist Temporal Classification With Attention Modeling
In this study, we propose advancing all-neural speech recognition by directly incorporating attention modeling within the Connectionist Temporal Classification (CTC) framework.
Acoustic-To-Word Model Without OOV
However, this type of word-based CTC model suffers from the out-of-vocabulary (OOV) issue as it can only model limited number of words in the output layer and maps all the remaining words into an OOV output node.
Improved training for online end-to-end speech recognition systems
Achieving high accuracy with end-to-end speech recognizers requires careful parameter initialization prior to training.
Large-Scale Domain Adaptation via Teacher-Student Learning
High accuracy speech recognition requires a large amount of transcribed data for supervised training.
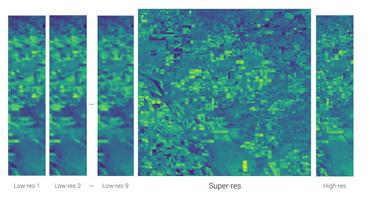
A Nuclear-norm Model for Multi-Frame Super-Resolution Reconstruction from Video Clips
Then a low-rank model is used to construct the reference frame in high-resolution by incorporating the information of the low-resolution frames.
Two-Stream RNN/CNN for Action Recognition in 3D Videos
The recognition of actions from video sequences has many applications in health monitoring, assisted living, surveillance, and smart homes.

Automated Low-cost Terrestrial Laser Scanner for Measuring Diameters at Breast Height and Heights of Forest Trees
The new scanner was named as BEE, which can scan the forest trees in three dimension.
Deep Learning and Its Applications to Machine Health Monitoring: A Survey
Since 2006, deep learning (DL) has become a rapidly growing research direction, redefining state-of-the-art performances in a wide range of areas such as object recognition, image segmentation, speech recognition and machine translation.
Facial Expression Intensity Estimation Using Ordinal Information
In fully supervised case, all the frames are provided with intensity annotations.
Saliency Detection by Multi-Context Deep Learning
Low-level saliency cues or priors do not produce good enough saliency detection results especially when the salient object presents in a low-contrast background with confusing visual appearance.
Highly Efficient Forward and Backward Propagation of Convolutional Neural Networks for Pixelwise Classification
The proposed algorithms eliminate all the redundant computation in convolution and pooling on images by introducing novel d-regularly sparse kernels.
Person Re-identification by Saliency Learning
(3) saliency matching is proposed based on patch matching.
Nilpotent matrices having a given Jordan type as maximum commuting nilpotent orbit
In 2012 P. Oblak formulated a conjecture concerning the cardinality of the set of partitions $P$ such that ${\mathcal Q}(P)$ is a given stable partition $ Q$ with two parts, and proved some special cases.
Rings and Algebras Commutative Algebra Representation Theory 15A27 (Primary), 05E40 (Secondary), 13E10, 15A21
Learning Mid-level Filters for Person Re-identification
In this paper, we propose a novel approach of learning mid-level filters from automatically discovered patch clusters for person re-identification.
DeepReID: Deep Filter Pairing Neural Network for Person Re-Identification
In this paper, we propose a novel filter pairing neural network (FPNN) to jointly handle misalignment, photometric and geometric transforms, occlusions and background clutter.
Unsupervised Salience Learning for Person Re-identification
In this paper, we propose a novel perspective for person re-identification based on unsupervised salience learning.
