 Video Model Blocks
Video Model Blocks
FuseFormer Block
Introduced by Liu et al. in FuseFormer: Fusing Fine-Grained Information in Transformers for Video InpaintingA FuseFormer block is used in the FuseFormer model for video inpainting. It is the same to standard Transformer block except that feed forward network is replaced with a Fusion Feed Forward Network (F3N). F3N brings no extra parameter into the standard feed forward net and the difference is that F3N inserts a soft-split and a soft composite operation between the two layer of MLPs.
Source: FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting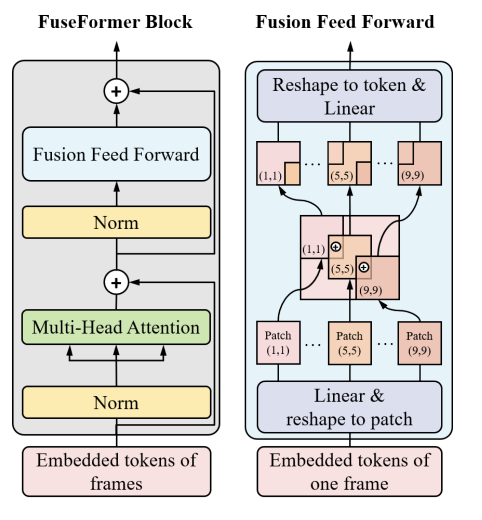
Papers
| Paper | Code | Results | Date | Stars |
|---|
 Dense Connections
Dense Connections
 Layer Normalization
Layer Normalization
 Multi-Head Attention
Multi-Head Attention
 Residual Connection
Residual Connection
 Scaled Dot-Product Attention
Scaled Dot-Product Attention
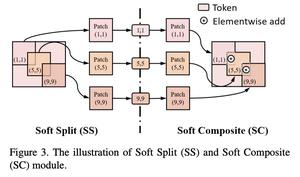 Soft Split and Soft Composition
Soft Split and Soft Composition
