 Generative Audio Models
Generative Audio Models
WaveNet
Introduced by Oord et al. in WaveNet: A Generative Model for Raw AudioWaveNet is an audio generative model based on the PixelCNN architecture. In order to deal with long-range temporal dependencies needed for raw audio generation, architectures are developed based on dilated causal convolutions, which exhibit very large receptive fields.
The joint probability of a waveform $\vec{x} = { x_1, \dots, x_T }$ is factorised as a product of conditional probabilities as follows:
$$p\left(\vec{x}\right) = \prod_{t=1}^{T} p\left(x_t \mid x_1, \dots ,x_{t-1}\right)$$
Each audio sample $x_t$ is therefore conditioned on the samples at all previous timesteps.
Source: WaveNet: A Generative Model for Raw Audio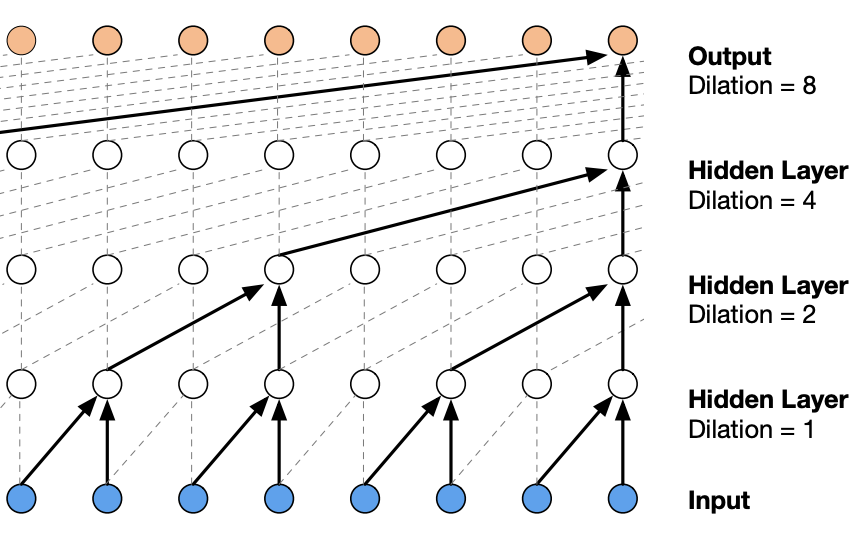
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Speech Synthesis | 53 | 24.88% |
| Text-To-Speech Synthesis | 16 | 7.51% |
| Voice Conversion | 12 | 5.63% |
| Audio Generation | 8 | 3.76% |
| Speech Enhancement | 6 | 2.82% |
| Time Series Analysis | 5 | 2.35% |
| Speech Recognition | 5 | 2.35% |
| Translation | 5 | 2.35% |
| Music Generation | 4 | 1.88% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 Dilated Causal Convolution
Dilated Causal Convolution
|
Temporal Convolutions | |
 Mixture of Logistic Distributions
Mixture of Logistic Distributions
|
Output Functions |
