ADELIE: Aligning Large Language Models on Information Extraction
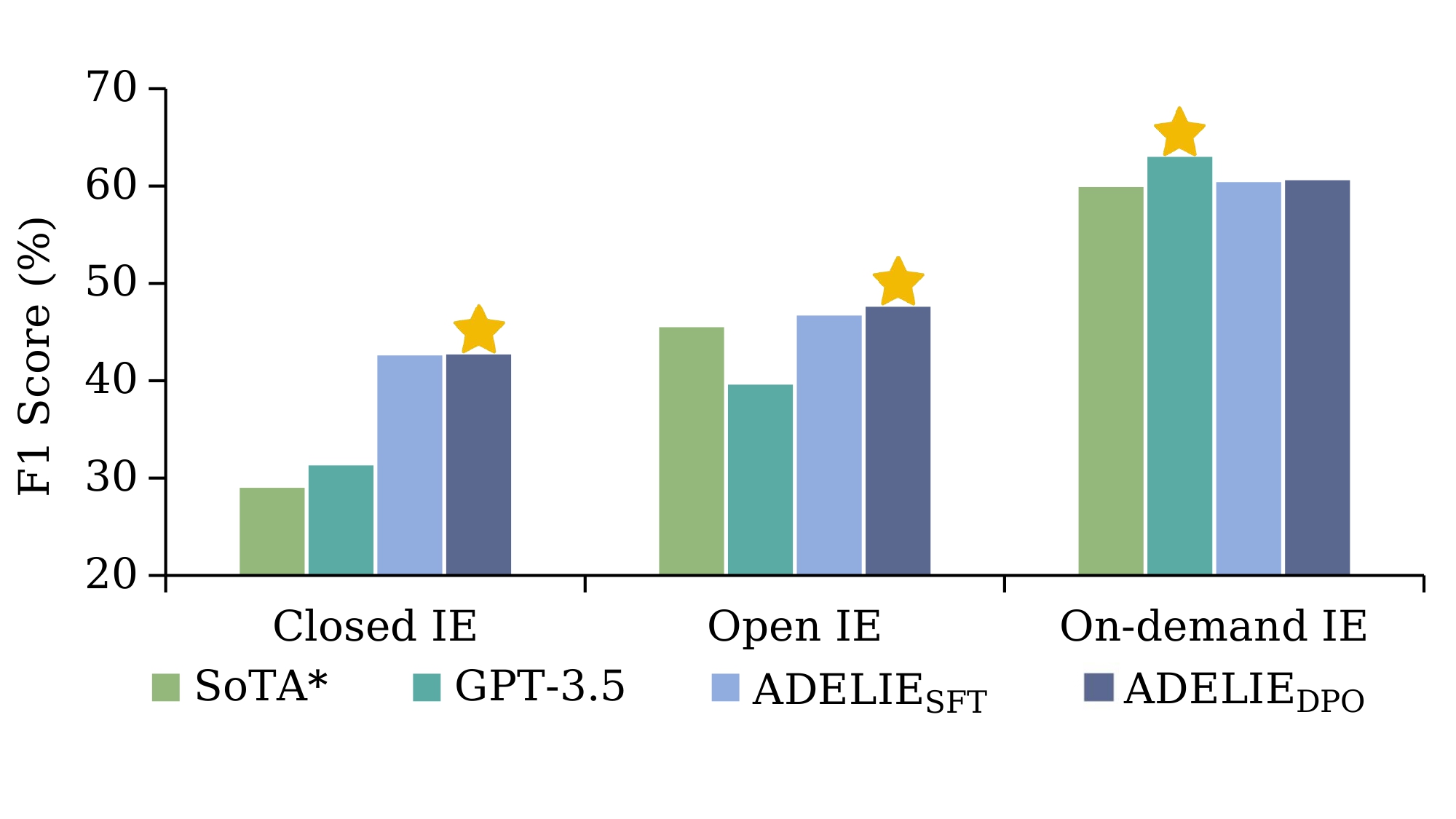
Large language models (LLMs) usually fall short on information extraction (IE) tasks and struggle to follow the complex instructions of IE tasks. This primarily arises from LLMs not being aligned with humans, as mainstream alignment datasets typically do not include IE data. In this paper, we introduce ADELIE (Aligning large language moDELs on Information Extraction), an aligned LLM that effectively solves various IE tasks, including closed IE, open IE, and on-demand IE. We first collect and construct a high-quality alignment corpus IEInstruct for IE. Then we train ADELIE_SFT using instruction tuning on IEInstruct. We further train ADELIE_SFT with direct preference optimization (DPO) objective, resulting in ADELIE_DPO. Extensive experiments on various held-out IE datasets demonstrate that our models (ADELIE_SFT and ADELIE_DPO) achieve state-of-the-art (SoTA) performance among open-source models. We further explore the general capabilities of ADELIE, and experimental results reveal that their general capabilities do not exhibit a noticeable decline. We will release the code, data, and models to facilitate further research.
PDF Abstract
 MMLU
MMLU
