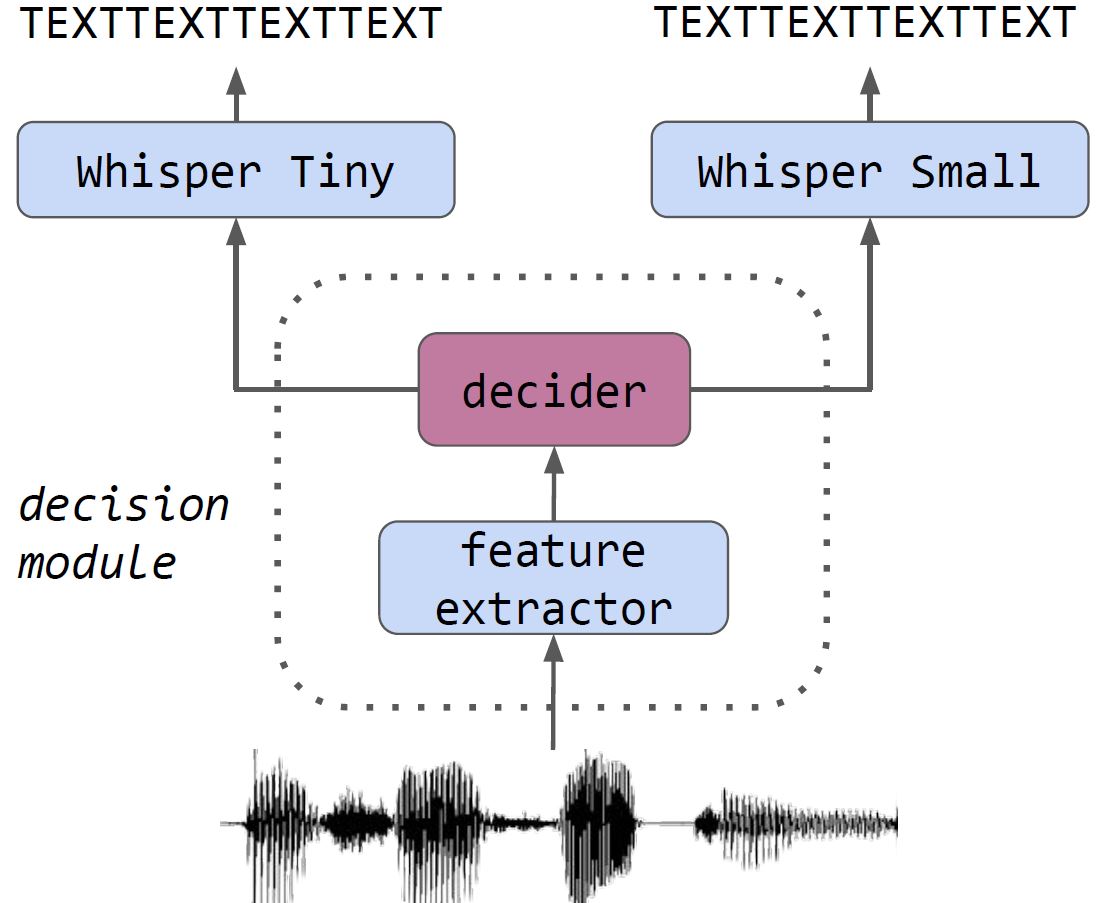
Big model only for hard audios: Sample dependent Whisper model selection for efficient inferences
Recent progress in Automatic Speech Recognition (ASR) has been coupled with a substantial increase in the model sizes, which may now contain billions of parameters, leading to slow inferences even with adapted hardware. In this context, several ASR models exist in various sizes, with different inference costs leading to different performance levels. Based on the observation that smaller models perform optimally on large parts of testing corpora, we propose to train a decision module, that would allow, given an audio sample, to use the smallest sufficient model leading to a good transcription. We apply our approach to two Whisper models with different sizes. By keeping the decision process computationally efficient, we build a decision module that allows substantial computational savings with reduced performance drops.
PDF Abstract


 LibriSpeech
LibriSpeech
 Common Voice
Common Voice
