BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation
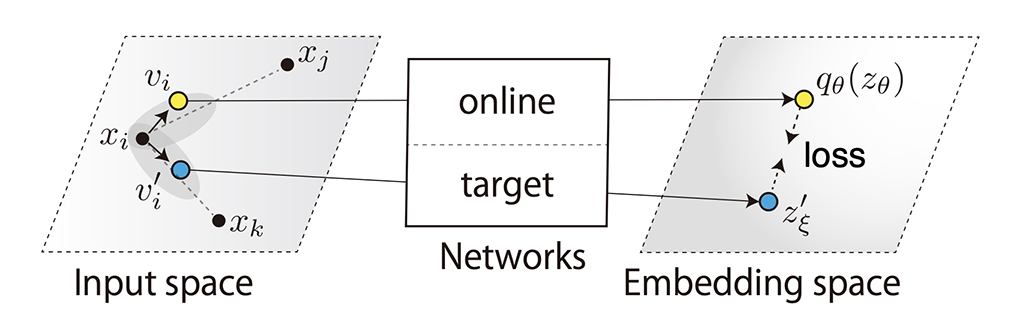
Inspired by the recent progress in self-supervised learning for computer vision that generates supervision using data augmentations, we explore a new general-purpose audio representation learning approach. We propose learning general-purpose audio representation from a single audio segment without expecting relationships between different time segments of audio samples. To implement this principle, we introduce Bootstrap Your Own Latent (BYOL) for Audio (BYOL-A, pronounced "viola"), an audio self-supervised learning method based on BYOL for learning general-purpose audio representation. Unlike most previous audio self-supervised learning methods that rely on agreement of vicinity audio segments or disagreement of remote ones, BYOL-A creates contrasts in an augmented audio segment pair derived from a single audio segment. With a combination of normalization and augmentation techniques, BYOL-A achieves state-of-the-art results in various downstream tasks. Extensive ablation studies also clarified the contribution of each component and their combinations.
PDF Abstract
 Colab
Colab


 VoxCeleb1
VoxCeleb1
 AudioSet
AudioSet
 Speech Commands
Speech Commands
 UrbanSound8K
UrbanSound8K
 NSynth
NSynth
 FSD50K
FSD50K
 VoxForge
VoxForge
