CMGAN: Conformer-Based Metric-GAN for Monaural Speech Enhancement
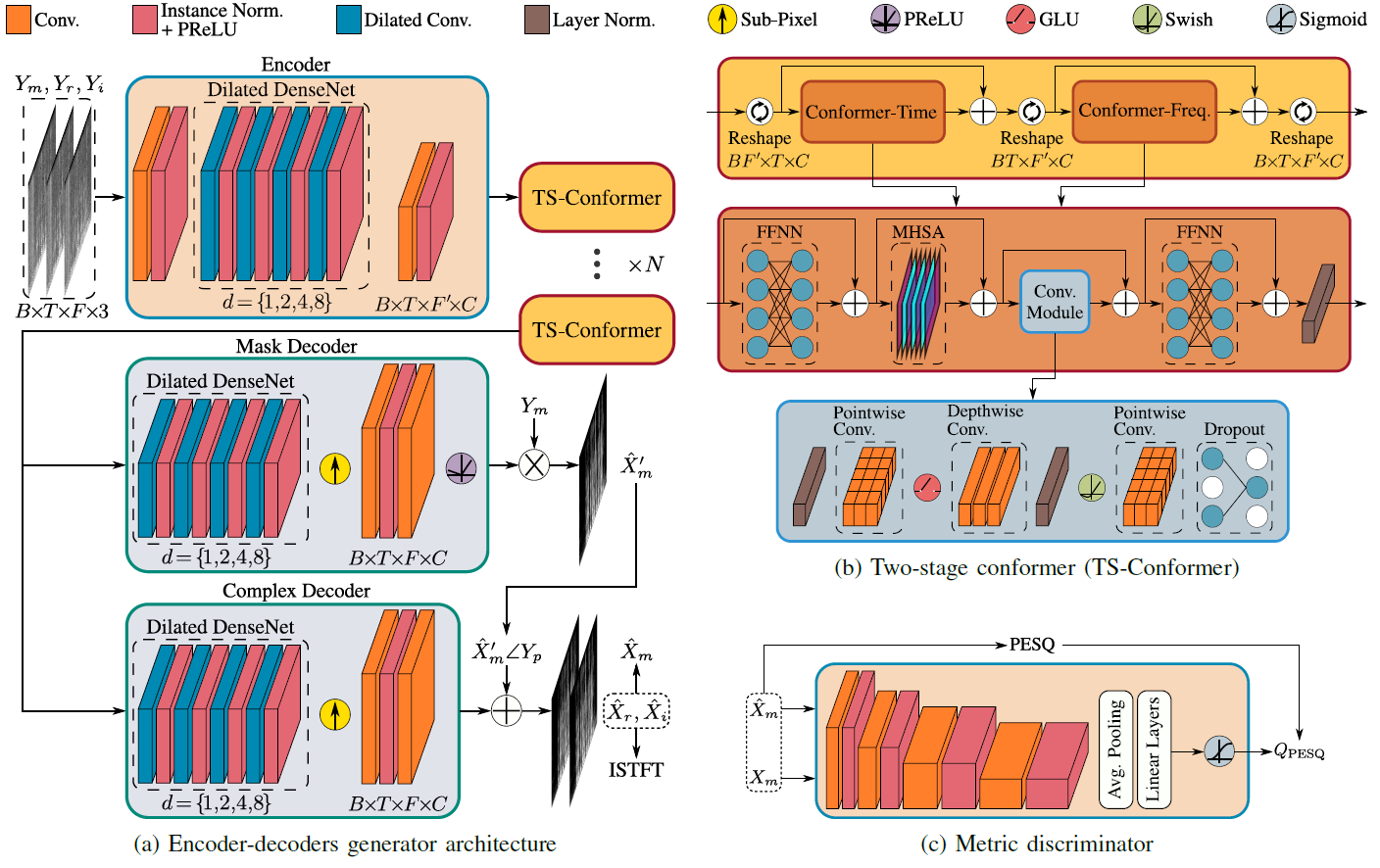
In this work, we further develop the conformer-based metric generative adversarial network (CMGAN) model for speech enhancement (SE) in the time-frequency (TF) domain. This paper builds on our previous work but takes a more in-depth look by conducting extensive ablation studies on model inputs and architectural design choices. We rigorously tested the generalization ability of the model to unseen noise types and distortions. We have fortified our claims through DNS-MOS measurements and listening tests. Rather than focusing exclusively on the speech denoising task, we extend this work to address the dereverberation and super-resolution tasks. This necessitated exploring various architectural changes, specifically metric discriminator scores and masking techniques. It is essential to highlight that this is among the earliest works that attempted complex TF-domain super-resolution. Our findings show that CMGAN outperforms existing state-of-the-art methods in the three major speech enhancement tasks: denoising, dereverberation, and super-resolution. For example, in the denoising task using the Voice Bank+DEMAND dataset, CMGAN notably exceeded the performance of prior models, attaining a PESQ score of 3.41 and an SSNR of 11.10 dB. Audio samples and CMGAN implementations are available online.
PDF Abstract






 VoiceBank + DEMAND
VoiceBank + DEMAND

