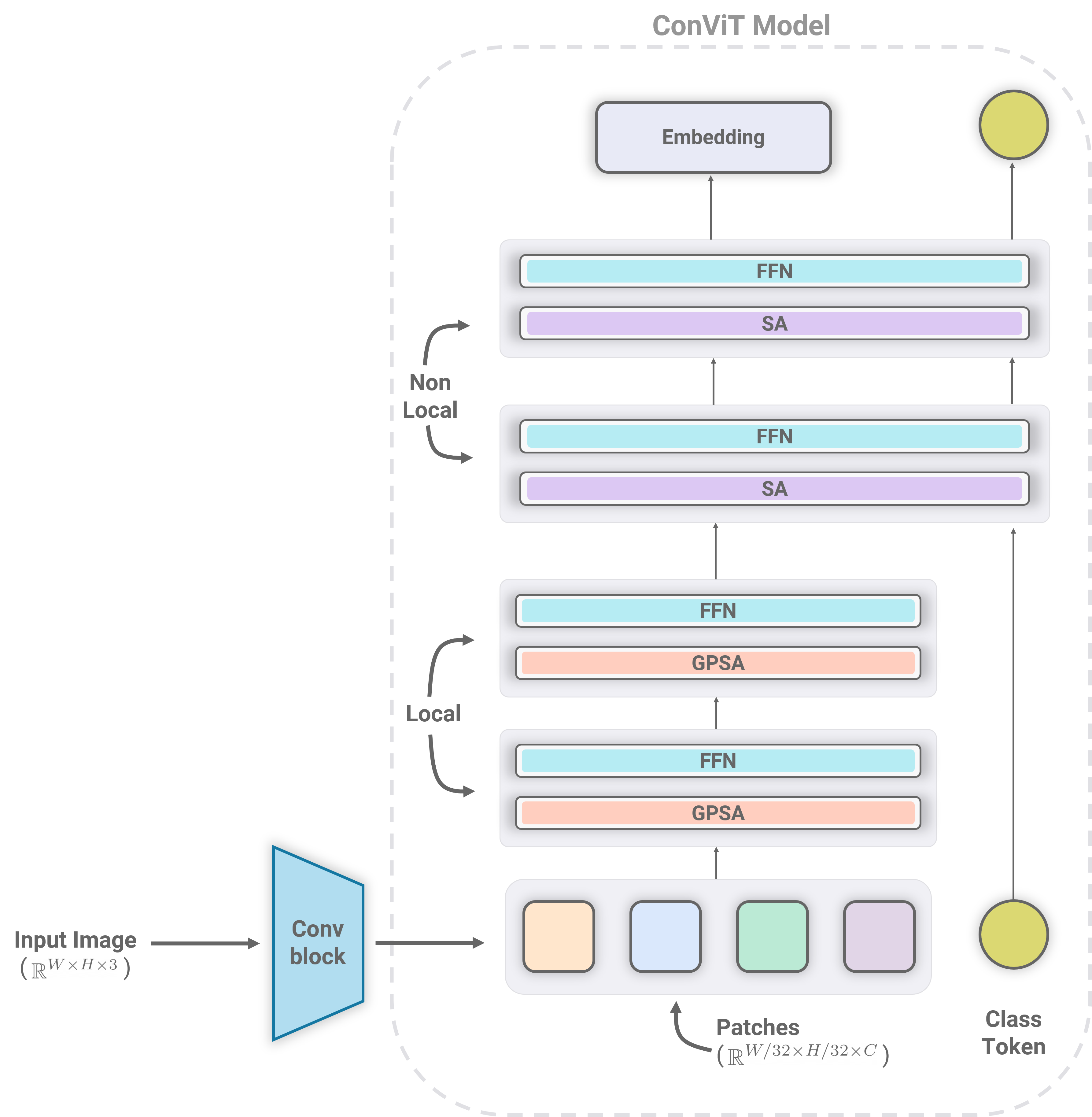
Conviformers: Convolutionally guided Vision Transformer
Vision transformers are nowadays the de-facto choice for image classification tasks. There are two broad categories of classification tasks, fine-grained and coarse-grained. In fine-grained classification, the necessity is to discover subtle differences due to the high level of similarity between sub-classes. Such distinctions are often lost as we downscale the image to save the memory and computational cost associated with vision transformers (ViT). In this work, we present an in-depth analysis and describe the critical components for developing a system for the fine-grained categorization of plants from herbarium sheets. Our extensive experimental analysis indicated the need for a better augmentation technique and the ability of modern-day neural networks to handle higher dimensional images. We also introduce a convolutional transformer architecture called Conviformer which, unlike the popular Vision Transformer (ConViT), can handle higher resolution images without exploding memory and computational cost. We also introduce a novel, improved pre-processing technique called PreSizer to resize images better while preserving their original aspect ratios, which proved essential for classifying natural plants. With our simple yet effective approach, we achieved SoTA on Herbarium 202x and iNaturalist 2019 dataset.
PDF Abstract


 iNaturalist
iNaturalist
 Herbarium 2021 Half–Earth
Herbarium 2021 Half–Earth
 Herbarium 2022
Herbarium 2022
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Fine-Grained Image Classification | Herbarium 2021 Half–Earth | Conviformer-B | Test F1 score | .719 | # 1 | |
| Fine-Grained Image Classification | Herbarium 2022 | Conviformer-B | Test F1 score (private) | .868 | # 1 | |
| Image Classification | iNaturalist 2019 | Conviformer-B | Top-1 Accuracy | 82.85 | # 5 |
