Distilling Large Vision-Language Model with Out-of-Distribution Generalizability
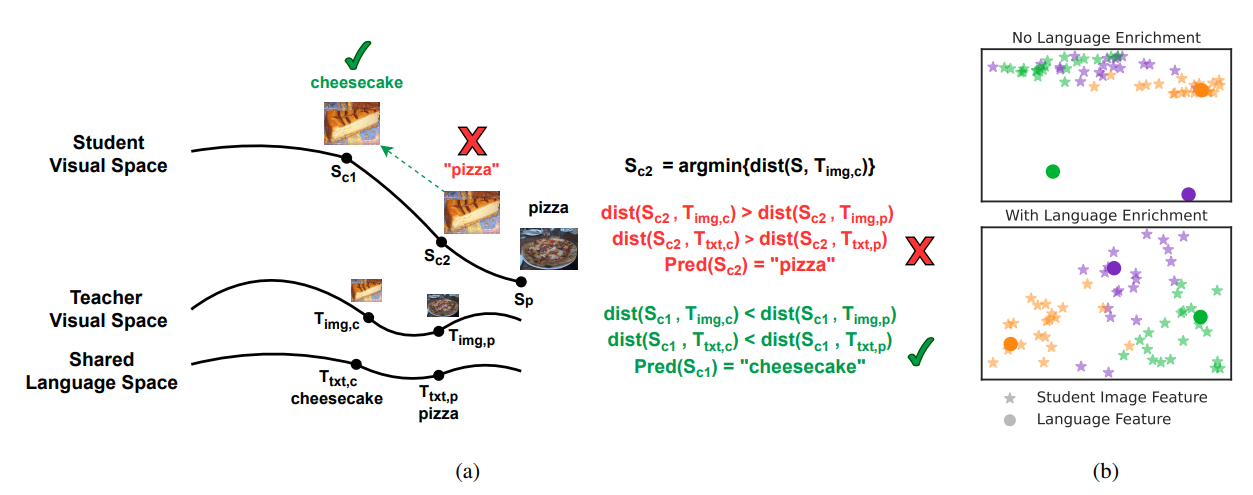
Large vision-language models have achieved outstanding performance, but their size and computational requirements make their deployment on resource-constrained devices and time-sensitive tasks impractical. Model distillation, the process of creating smaller, faster models that maintain the performance of larger models, is a promising direction towards the solution. This paper investigates the distillation of visual representations in large teacher vision-language models into lightweight student models using a small- or mid-scale dataset. Notably, this study focuses on open-vocabulary out-of-distribution (OOD) generalization, a challenging problem that has been overlooked in previous model distillation literature. We propose two principles from vision and language modality perspectives to enhance student's OOD generalization: (1) by better imitating teacher's visual representation space, and carefully promoting better coherence in vision-language alignment with the teacher; (2) by enriching the teacher's language representations with informative and finegrained semantic attributes to effectively distinguish between different labels. We propose several metrics and conduct extensive experiments to investigate their techniques. The results demonstrate significant improvements in zero-shot and few-shot student performance on open-vocabulary out-of-distribution classification, highlighting the effectiveness of our proposed approaches. Poster: https://xuanlinli17.github.io/pdfs/iccv23_large_vlm_distillation_poster.pdf Code: https://github.com/xuanlinli17/large_vlm_distillation_ood
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract







 ImageNet
ImageNet
 CUB-200-2011
CUB-200-2011
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
 Food-101
Food-101
 SUN397
SUN397
