DiVA: Diverse Visual Feature Aggregation for Deep Metric Learning
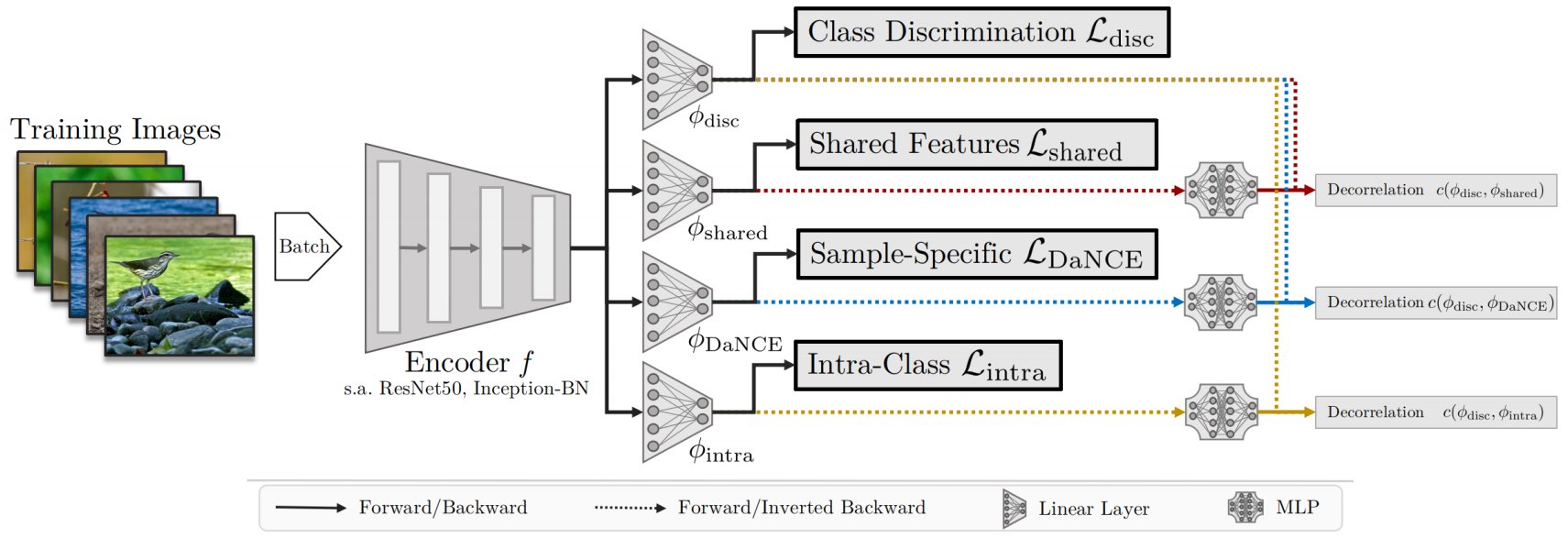
Visual Similarity plays an important role in many computer vision applications. Deep metric learning (DML) is a powerful framework for learning such similarities which not only generalize from training data to identically distributed test distributions, but in particular also translate to unknown test classes. However, its prevailing learning paradigm is class-discriminative supervised training, which typically results in representations specialized in separating training classes. For effective generalization, however, such an image representation needs to capture a diverse range of data characteristics. To this end, we propose and study multiple complementary learning tasks, targeting conceptually different data relationships by only resorting to the available training samples and labels of a standard DML setting. Through simultaneous optimization of our tasks we learn a single model to aggregate their training signals, resulting in strong generalization and state-of-the-art performance on multiple established DML benchmark datasets.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract
Tasks

Datasets
 CUB-200-2011
CUB-200-2011
 Stanford Online Products
Stanford Online Products
Results from the Paper
 Ranked #13 on
Metric Learning
on CUB-200-2011
(using extra training data)
Ranked #13 on
Metric Learning
on CUB-200-2011
(using extra training data)
