DreamView: Injecting View-specific Text Guidance into Text-to-3D Generation
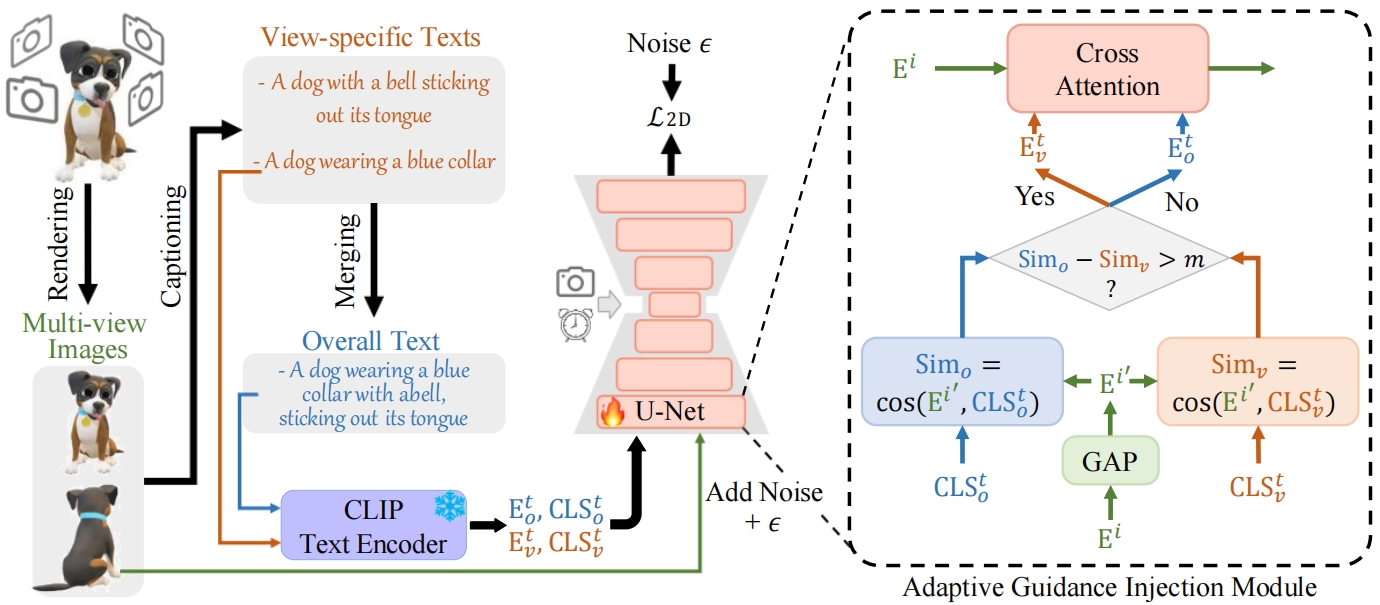
Text-to-3D generation, which synthesizes 3D assets according to an overall text description, has significantly progressed. However, a challenge arises when the specific appearances need customizing at designated viewpoints but referring solely to the overall description for generating 3D objects. For instance, ambiguity easily occurs when producing a T-shirt with distinct patterns on its front and back using a single overall text guidance. In this work, we propose DreamView, a text-to-image approach enabling multi-view customization while maintaining overall consistency by adaptively injecting the view-specific and overall text guidance through a collaborative text guidance injection module, which can also be lifted to 3D generation via score distillation sampling. DreamView is trained with large-scale rendered multi-view images and their corresponding view-specific texts to learn to balance the separate content manipulation in each view and the global consistency of the overall object, resulting in a dual achievement of customization and consistency. Consequently, DreamView empowers artists to design 3D objects creatively, fostering the creation of more innovative and diverse 3D assets. Code and model will be released at https://github.com/iSEE-Laboratory/DreamView.
PDF Abstract
 Spaces
Spaces

 Objaverse
Objaverse
