Genetic Quantization-Aware Approximation for Non-Linear Operations in Transformers
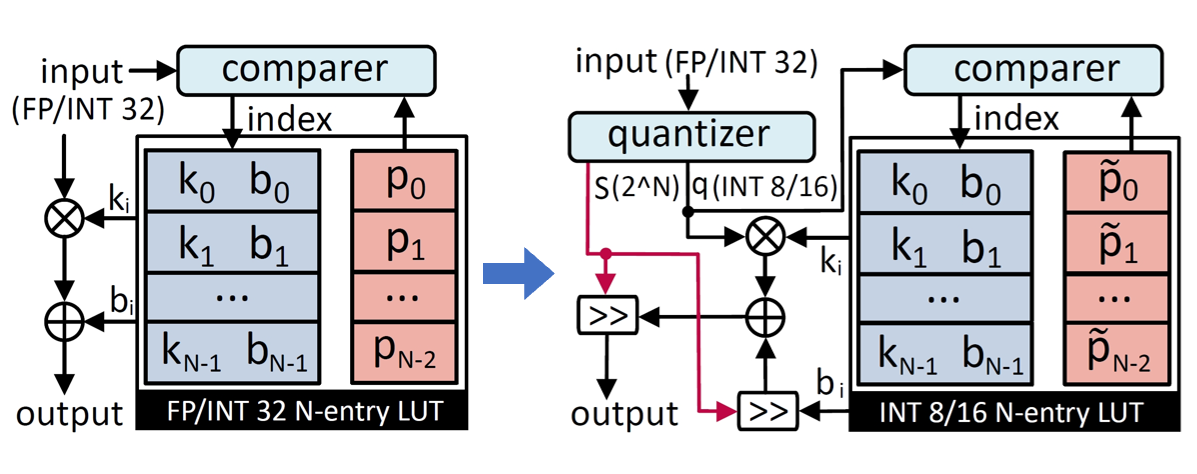
Non-linear functions are prevalent in Transformers and their lightweight variants, incurring substantial and frequently underestimated hardware costs. Previous state-of-the-art works optimize these operations by piece-wise linear approximation and store the parameters in look-up tables (LUT), but most of them require unfriendly high-precision arithmetics such as FP/INT 32 and lack consideration of integer-only INT quantization. This paper proposed a genetic LUT-Approximation algorithm namely GQA-LUT that can automatically determine the parameters with quantization awareness. The results demonstrate that GQA-LUT achieves negligible degradation on the challenging semantic segmentation task for both vanilla and linear Transformer models. Besides, proposed GQA-LUT enables the employment of INT8-based LUT-Approximation that achieves an area savings of 81.3~81.7% and a power reduction of 79.3~80.2% compared to the high-precision FP/INT 32 alternatives. Code is available at https:// github.com/PingchengDong/GQA-LUT.
PDF Abstract


 Cityscapes
Cityscapes
