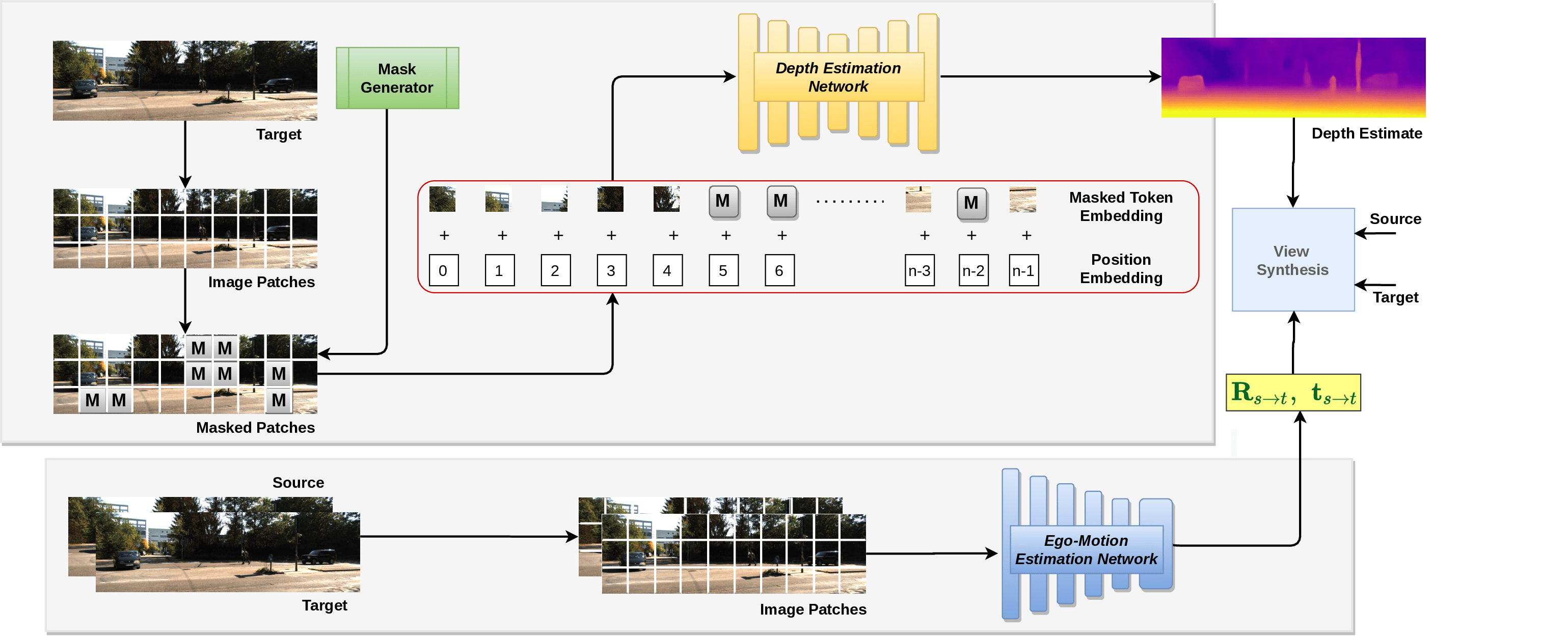
Image Masking for Robust Self-Supervised Monocular Depth Estimation
Self-supervised monocular depth estimation is a salient task for 3D scene understanding. Learned jointly with monocular ego-motion estimation, several methods have been proposed to predict accurate pixel-wise depth without using labeled data. Nevertheless, these methods focus on improving performance under ideal conditions without natural or digital corruptions. The general absence of occlusions is assumed even for object-specific depth estimation. These methods are also vulnerable to adversarial attacks, which is a pertinent concern for their reliable deployment in robots and autonomous driving systems. We propose MIMDepth, a method that adapts masked image modeling (MIM) for self-supervised monocular depth estimation. While MIM has been used to learn generalizable features during pre-training, we show how it could be adapted for direct training of monocular depth estimation. Our experiments show that MIMDepth is more robust to noise, blur, weather conditions, digital artifacts, occlusions, as well as untargeted and targeted adversarial attacks.
PDF Abstract




