Implicit Temporal Modeling with Learnable Alignment for Video Recognition
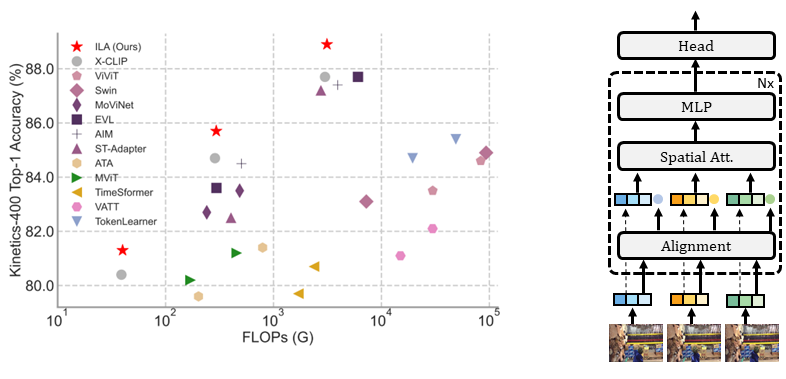
Contrastive language-image pretraining (CLIP) has demonstrated remarkable success in various image tasks. However, how to extend CLIP with effective temporal modeling is still an open and crucial problem. Existing factorized or joint spatial-temporal modeling trades off between the efficiency and performance. While modeling temporal information within straight through tube is widely adopted in literature, we find that simple frame alignment already provides enough essence without temporal attention. To this end, in this paper, we proposed a novel Implicit Learnable Alignment (ILA) method, which minimizes the temporal modeling effort while achieving incredibly high performance. Specifically, for a frame pair, an interactive point is predicted in each frame, serving as a mutual information rich region. By enhancing the features around the interactive point, two frames are implicitly aligned. The aligned features are then pooled into a single token, which is leveraged in the subsequent spatial self-attention. Our method allows eliminating the costly or insufficient temporal self-attention in video. Extensive experiments on benchmarks demonstrate the superiority and generality of our module. Particularly, the proposed ILA achieves a top-1 accuracy of 88.7% on Kinetics-400 with much fewer FLOPs compared with Swin-L and ViViT-H. Code is released at https://github.com/Francis-Rings/ILA .
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract



 ImageNet
ImageNet
 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
 Something-Something V2
Something-Something V2

