Improving Deep Neural Network with Multiple Parametric Exponential Linear Units
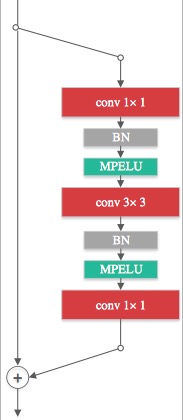
Activation function is crucial to the recent successes of deep neural networks. In this paper, we first propose a new activation function, Multiple Parametric Exponential Linear Units (MPELU), aiming to generalize and unify the rectified and exponential linear units. As the generalized form, MPELU shares the advantages of Parametric Rectified Linear Unit (PReLU) and Exponential Linear Unit (ELU), leading to better classification performance and convergence property. In addition, weight initialization is very important to train very deep networks. The existing methods laid a solid foundation for networks using rectified linear units but not for exponential linear units. This paper complements the current theory and extends it to the wider range. Specifically, we put forward a way of initialization, enabling training of very deep networks using exponential linear units. Experiments demonstrate that the proposed initialization not only helps the training process but leads to better generalization performance. Finally, utilizing the proposed activation function and initialization, we present a deep MPELU residual architecture that achieves state-of-the-art performance on the CIFAR-10/100 datasets. The code is available at https://github.com/Coldmooon/Code-for-MPELU.
PDF Abstract
 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
