Kronecker Attention Networks
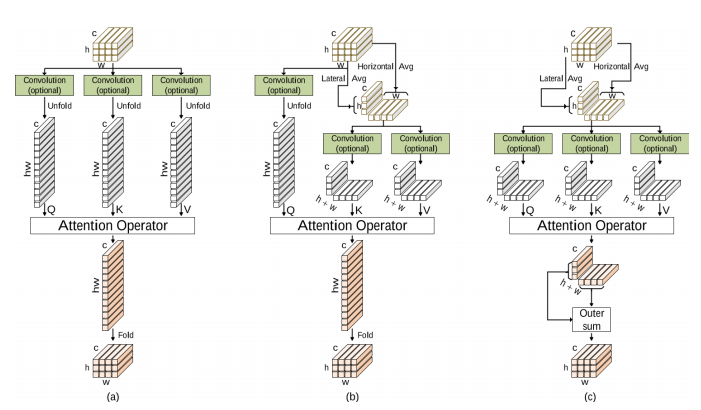
Attention operators have been applied on both 1-D data like texts and higher-order data such as images and videos. Use of attention operators on high-order data requires flattening of the spatial or spatial-temporal dimensions into a vector, which is assumed to follow a multivariate normal distribution. This not only incurs excessive requirements on computational resources, but also fails to preserve structures in data. In this work, we propose to avoid flattening by assuming the data follow matrix-variate normal distributions. Based on this new view, we develop Kronecker attention operators (KAOs) that operate on high-order tensor data directly. More importantly, the proposed KAOs lead to dramatic reductions in computational resources. Experimental results show that our methods reduce the amount of required computational resources by a factor of hundreds, with larger factors for higher-dimensional and higher-order data. Results also show that networks with KAOs outperform models without attention, while achieving competitive performance as those with original attention operators.
PDF Abstract ICLR 2020 PDF ICLR 2020 Abstract
 ImageNet
ImageNet
