Learning Classifiers on Positive and Unlabeled Data with Policy Gradient
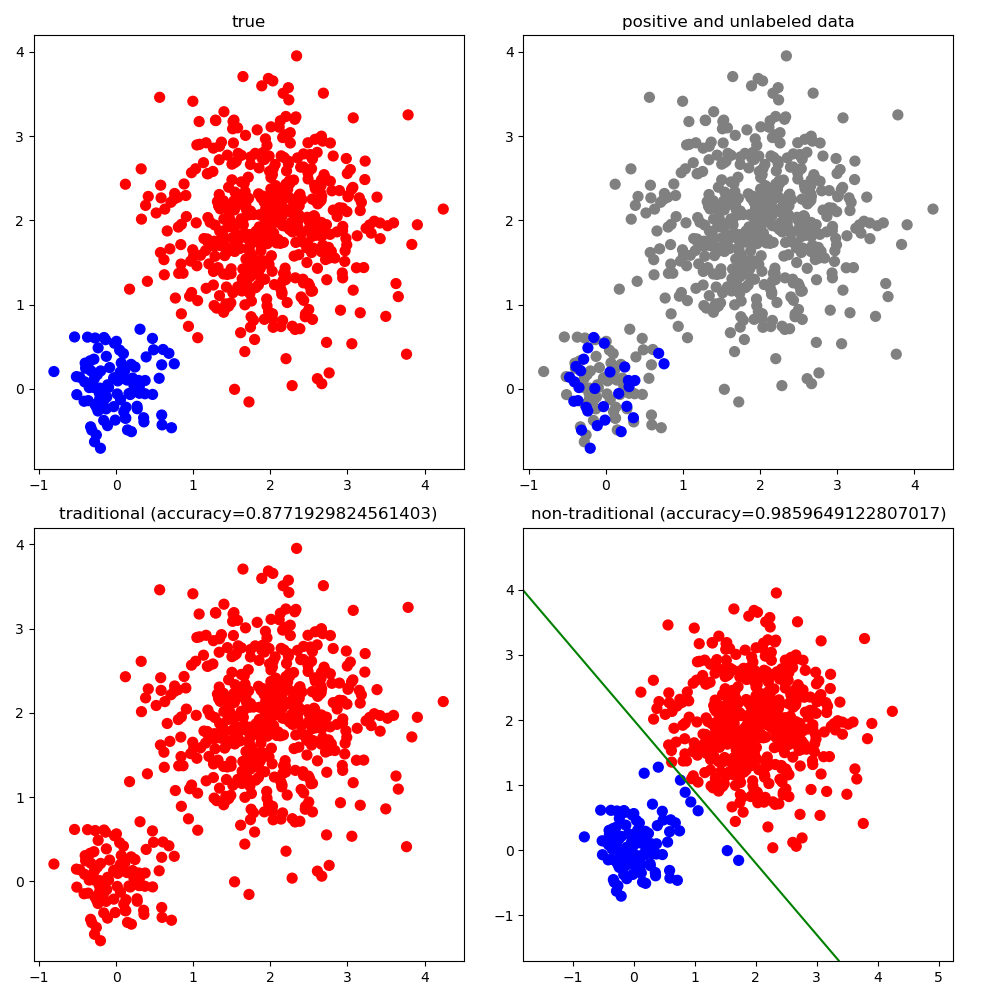
Existing algorithms aiming to learn a binary classifier from positive (P) and unlabeled (U) data generally require estimating the class prior or label noises ahead of building a classification model. However, the estimation and classifier learning are normally conducted in a pipeline instead of being jointly optimized. In this paper, we propose to alternatively train the two steps using reinforcement learning. Our proposal adopts a policy network to adaptively make assumptions on the labels of unlabeled data, while a classifier is built upon the output of the policy network and provides rewards to learn a better strategy. The dynamic and interactive training between the policy maker and the classifier can exploit the unlabeled data in a more effective manner and yield a significant improvement on the classification performance. Furthermore, we present two different approaches to represent the actions sampled from the policy. The first approach considers continuous actions as soft labels, while the other uses discrete actions as hard assignment of labels for unlabeled examples.We validate the effectiveness of the proposed method on two benchmark datasets as well as one e-commerce dataset. The result shows the proposed method is able to consistently outperform state-of-the-art methods in various settings.
PDF Abstract
