Learning Monocular Depth in Dynamic Scenes via Instance-Aware Projection Consistency
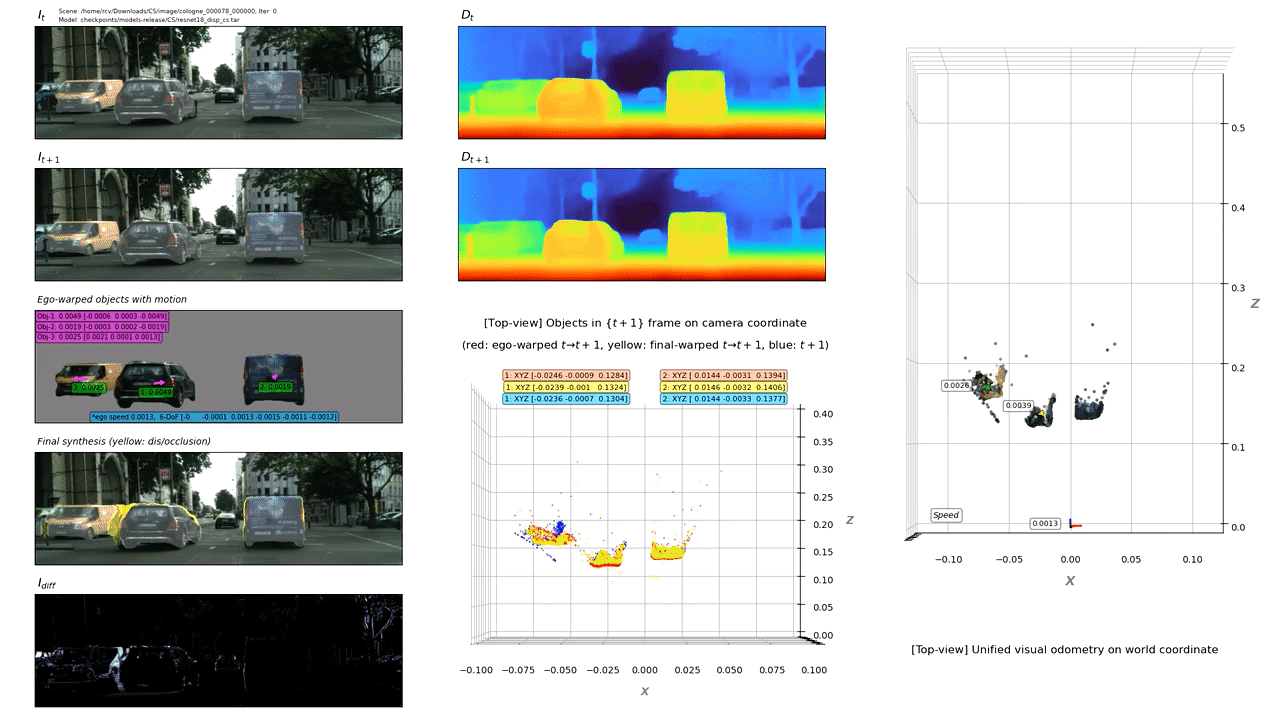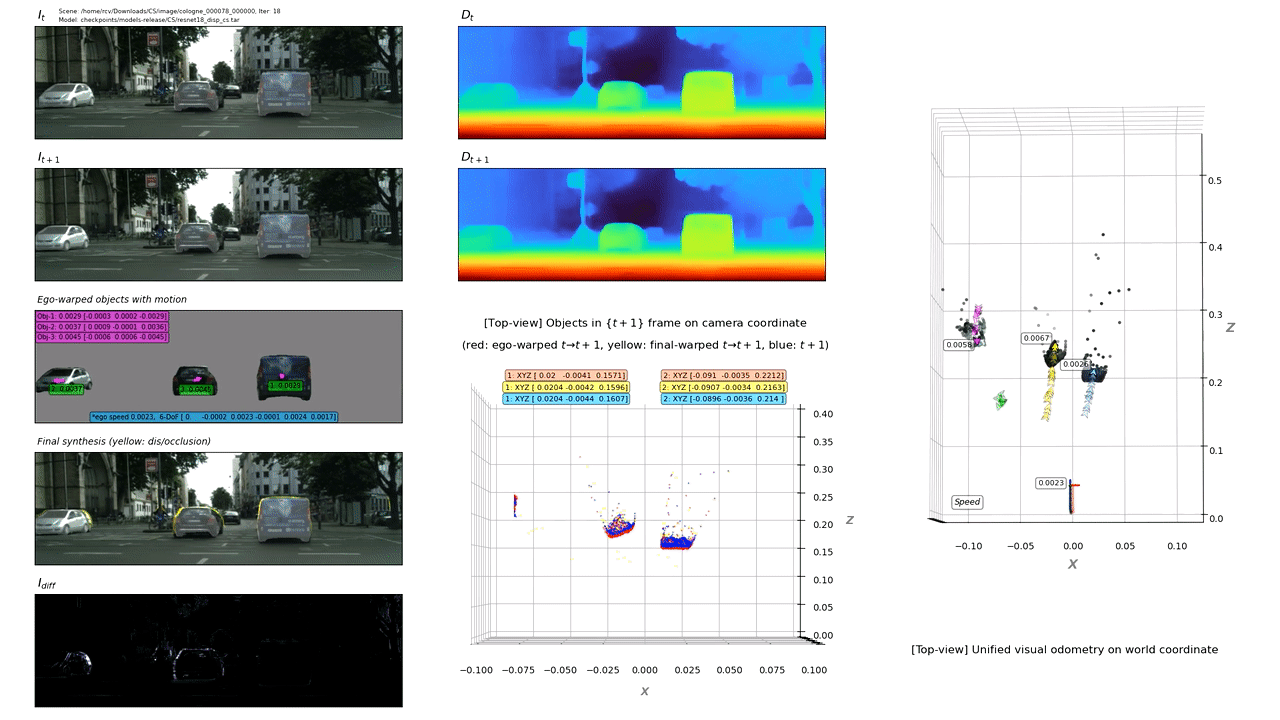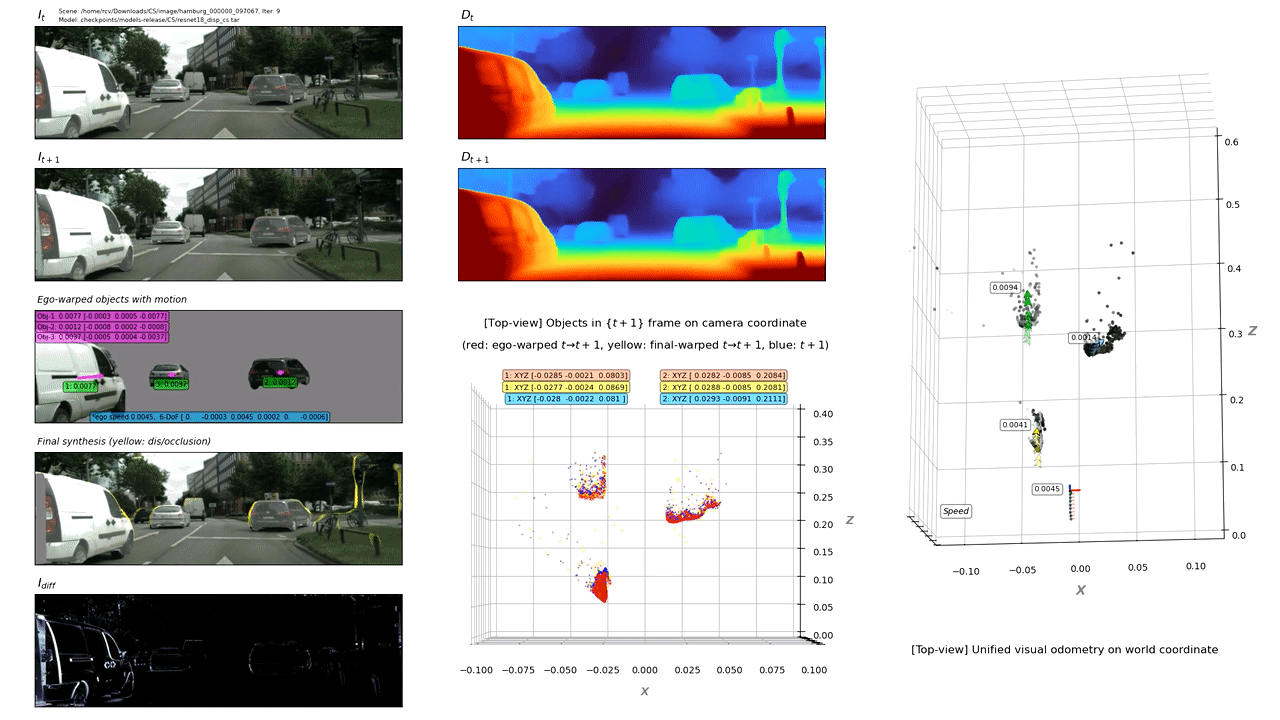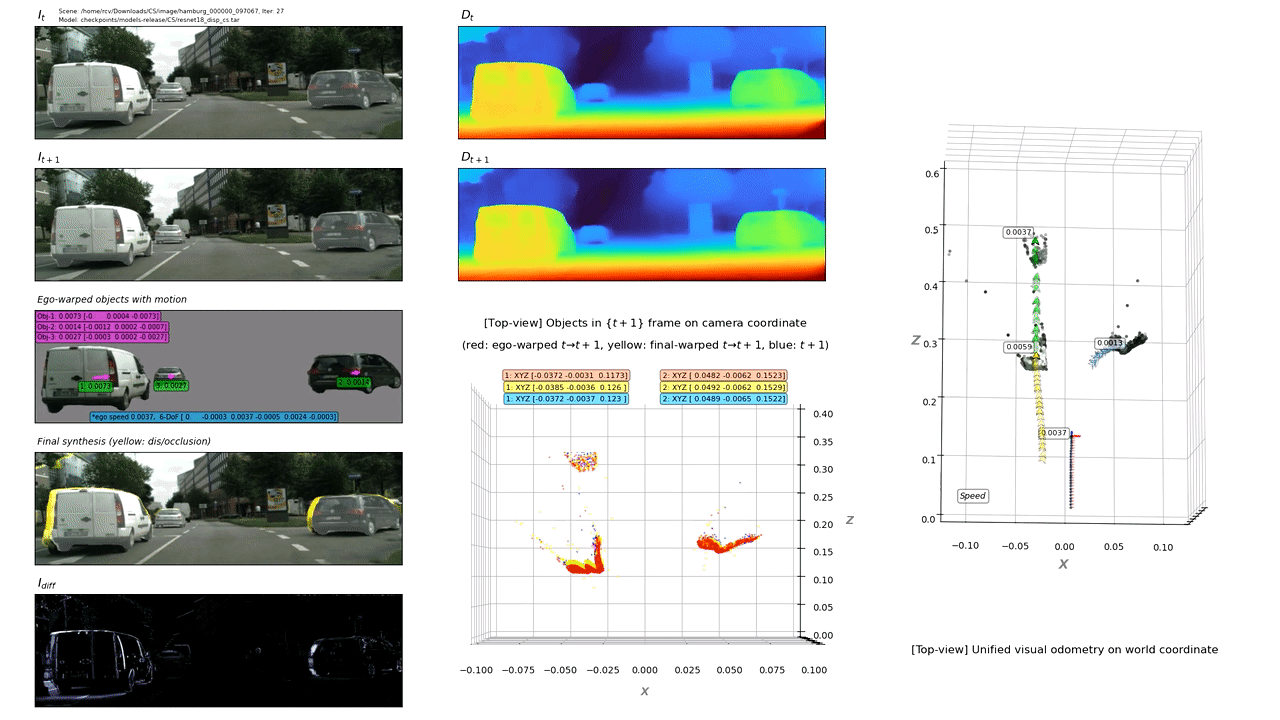
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. Our technical contributions are three-fold. First, we highlight the fundamental difference between inverse and forward projection while modeling the individual motion of each rigid object, and propose a geometrically correct projection pipeline using a neural forward projection module. Second, we design a unified instance-aware photometric and geometric consistency loss that holistically imposes self-supervisory signals for every background and object region. Lastly, we introduce a general-purpose auto-annotation scheme using any off-the-shelf instance segmentation and optical flow models to produce video instance segmentation maps that will be utilized as input to our training pipeline. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI and Cityscapes dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods. Our code, dataset, and models are available at https://github.com/SeokjuLee/Insta-DM .
PDF AbstractCode







Datasets
 Cityscapes
Cityscapes
 KITTI
KITTI

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Monocular Depth Estimation | Cityscapes | Lee et al. | Absolute relative error (AbsRel) | 0.111 | # 2 | |
| RMSE | 6.437 | # 2 | ||||
| RMSE log | 0.182 | # 2 | ||||
| Square relative error (SqRel) | 1.158 | # 2 | ||||
| Unsupervised Monocular Depth Estimation | Cityscapes | Lee et al. | RMSE | 6.437 | # 7 | |
| RMSE log | 0.182 | # 6 | ||||
| Square relative error (SqRel) | 1.158 | # 5 | ||||
| Absolute relative error (AbsRel) | 0.111 | # 5 | ||||
| Test frames | 1 | # 1 |
