Low-resource finetuning of foundation models beats state-of-the-art in histopathology
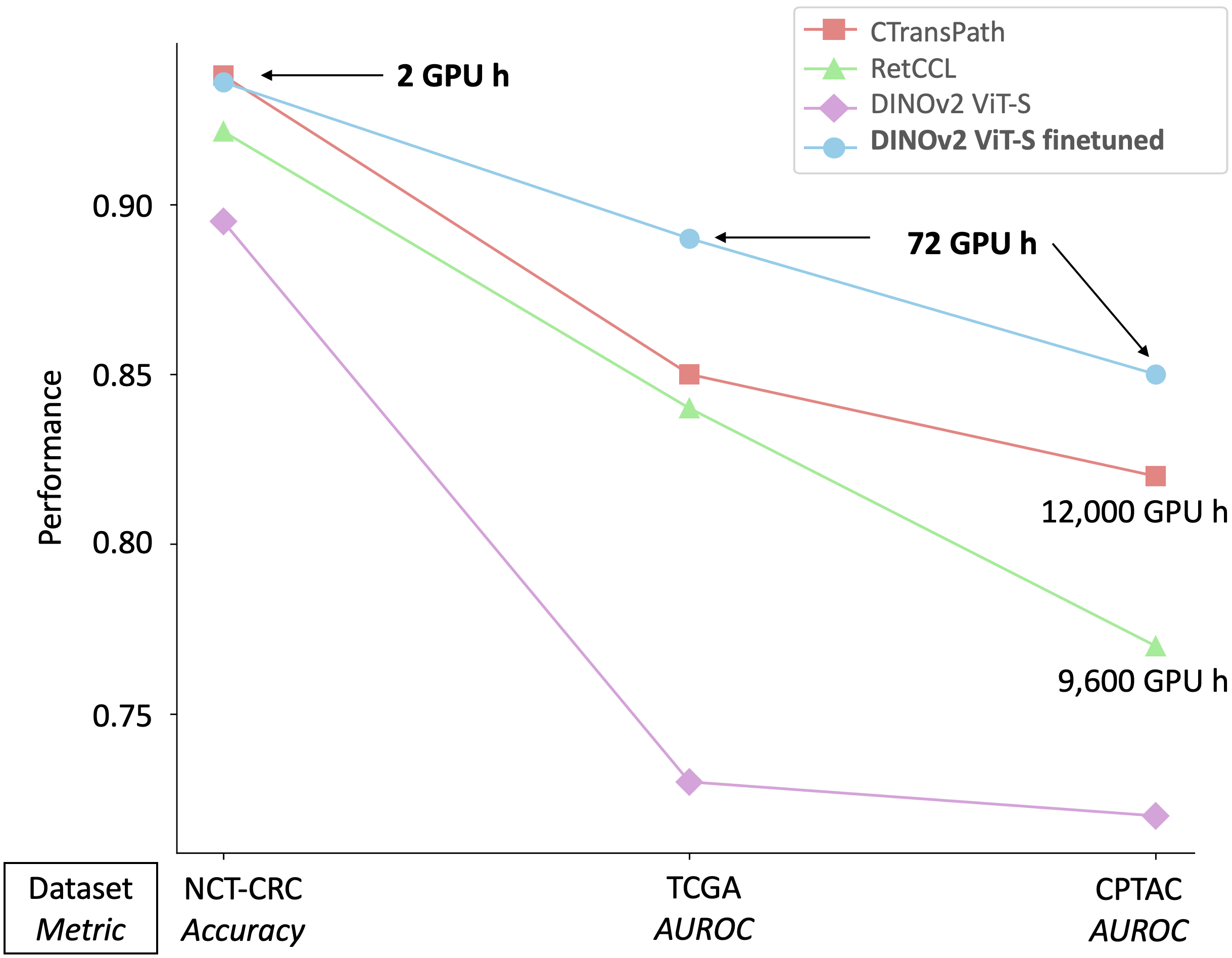
To handle the large scale of whole slide images in computational pathology, most approaches first tessellate the images into smaller patches, extract features from these patches, and finally aggregate the feature vectors with weakly-supervised learning. The performance of this workflow strongly depends on the quality of the extracted features. Recently, foundation models in computer vision showed that leveraging huge amounts of data through supervised or self-supervised learning improves feature quality and generalizability for a variety of tasks. In this study, we benchmark the most popular vision foundation models as feature extractors for histopathology data. We evaluate the models in two settings: slide-level classification and patch-level classification. We show that foundation models are a strong baseline. Our experiments demonstrate that by finetuning a foundation model on a single GPU for only two hours or three days depending on the dataset, we can match or outperform state-of-the-art feature extractors for computational pathology. These findings imply that even with little resources one can finetune a feature extractor tailored towards a specific downstream task and dataset. This is a considerable shift from the current state, where only few institutions with large amounts of resources and datasets are able to train a feature extractor. We publish all code used for training and evaluation as well as the finetuned models.
PDF Abstract


