Optimization of the Model Predictive Control Update Interval Using Reinforcement Learning
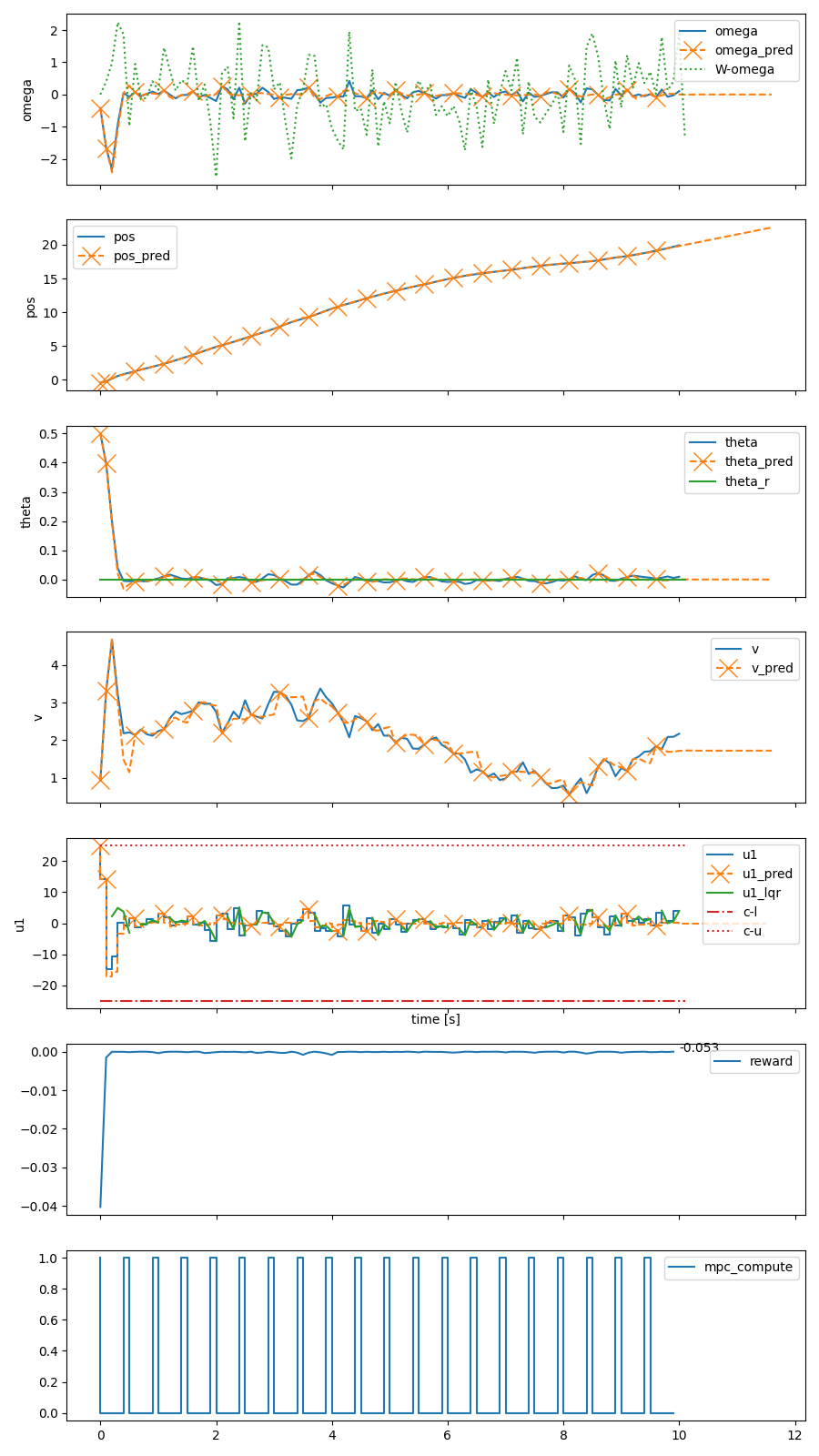
In control applications there is often a compromise that needs to be made with regards to the complexity and performance of the controller and the computational resources that are available. For instance, the typical hardware platform in embedded control applications is a microcontroller with limited memory and processing power, and for battery powered applications the control system can account for a significant portion of the energy consumption. We propose a controller architecture in which the computational cost is explicitly optimized along with the control objective. This is achieved by a three-part architecture where a high-level, computationally expensive controller generates plans, which a computationally simpler controller executes by compensating for prediction errors, while a recomputation policy decides when the plan should be recomputed. In this paper, we employ model predictive control (MPC) as the high-level plan-generating controller, a linear state feedback controller as the simpler compensating controller, and reinforcement learning (RL) to learn the recomputation policy. Simulation results for two examples showcase the architecture's ability to improve upon the MPC approach and find reasonable compromises weighing the performance on the control objective and the computational resources expended.
PDF Abstract
