OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation
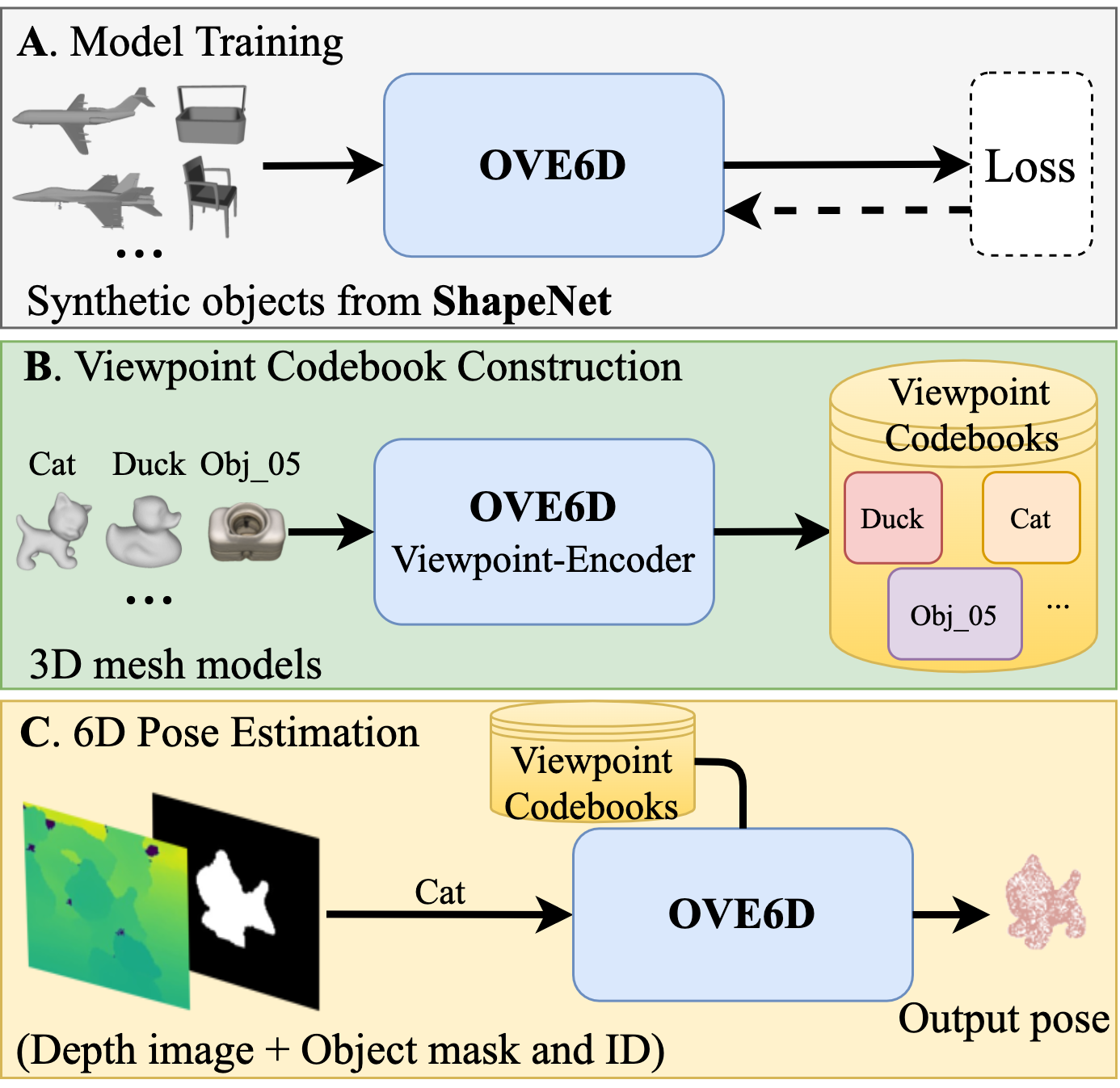
This paper proposes a universal framework, called OVE6D, for model-based 6D object pose estimation from a single depth image and a target object mask. Our model is trained using purely synthetic data rendered from ShapeNet, and, unlike most of the existing methods, it generalizes well on new real-world objects without any fine-tuning. We achieve this by decomposing the 6D pose into viewpoint, in-plane rotation around the camera optical axis and translation, and introducing novel lightweight modules for estimating each component in a cascaded manner. The resulting network contains less than 4M parameters while demonstrating excellent performance on the challenging T-LESS and Occluded LINEMOD datasets without any dataset-specific training. We show that OVE6D outperforms some contemporary deep learning-based pose estimation methods specifically trained for individual objects or datasets with real-world training data. The implementation and the pre-trained model will be made publicly available.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



 ShapeNet
ShapeNet
 T-LESS
T-LESS
