Parameter-Efficient Fine-Tuning with Layer Pruning on Free-Text Sequence-to-Sequence Modeling
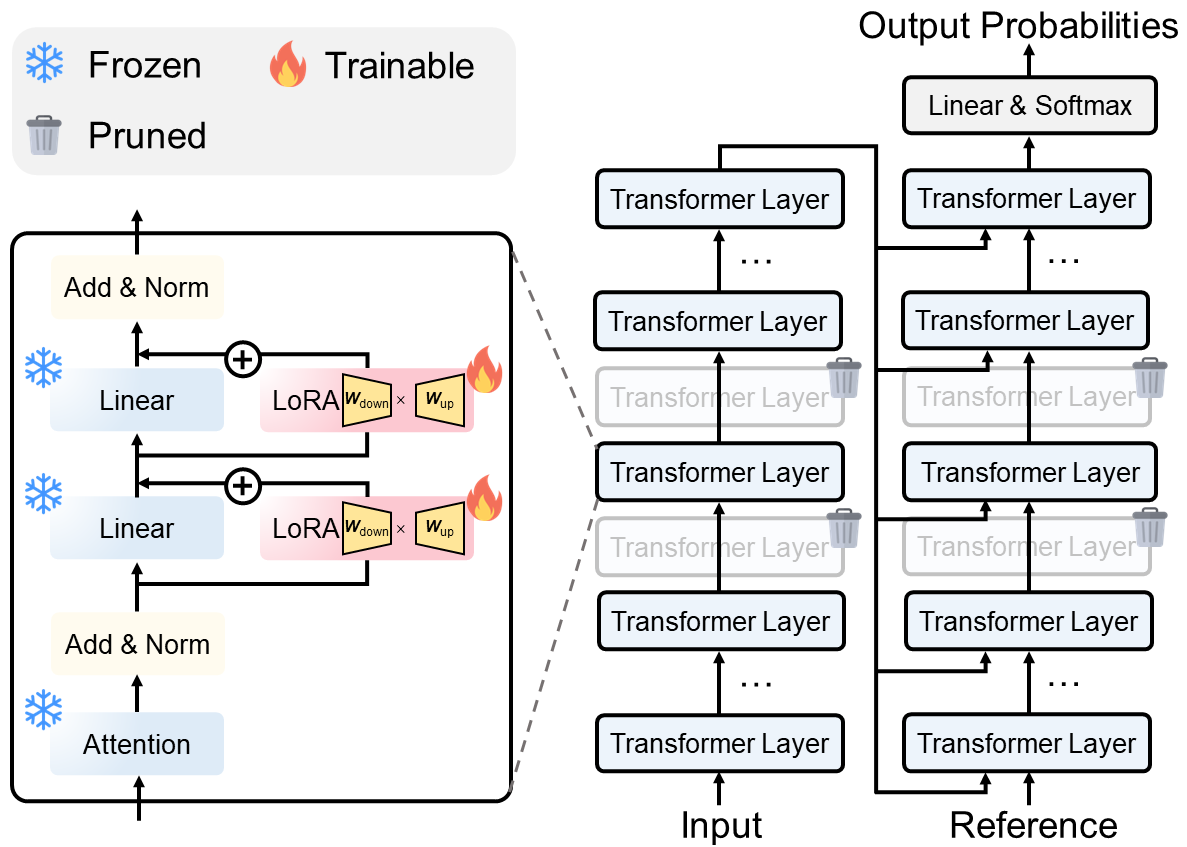
The increasing size of language models raises great research interests in parameter-efficient fine-tuning such as LoRA that freezes the pre-trained model, and injects small-scale trainable parameters for multiple downstream tasks (e.g., summarization, question answering and translation). To further enhance the efficiency of fine-tuning, we propose a framework that integrates LoRA and structured layer pruning. The integrated framework is validated on two created deidentified medical report summarization datasets based on MIMIC-IV-Note and two public medical dialogue datasets. By tuning 0.6% parameters of the original model and pruning over 30% Transformer-layers, our framework can reduce 50% of GPU memory usage and speed up 100% of the training phase, while preserving over 92% generation qualities on free-text sequence-to-sequence tasks.
PDF Abstract


