TensorQuant - A Simulation Toolbox for Deep Neural Network Quantization
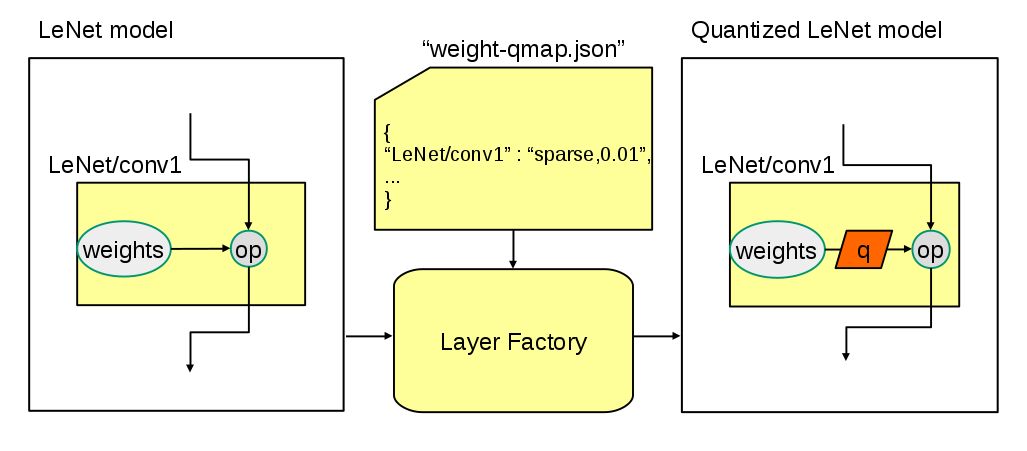
Recent research implies that training and inference of deep neural networks (DNN) can be computed with low precision numerical representations of the training/test data, weights and gradients without a general loss in accuracy. The benefit of such compact representations is twofold: they allow a significant reduction of the communication bottleneck in distributed DNN training and faster neural network implementations on hardware accelerators like FPGAs. Several quantization methods have been proposed to map the original 32-bit floating point problem to low-bit representations. While most related publications validate the proposed approach on a single DNN topology, it appears to be evident, that the optimal choice of the quantization method and number of coding bits is topology dependent. To this end, there is no general theory available, which would allow users to derive the optimal quantization during the design of a DNN topology. In this paper, we present a quantization tool box for the TensorFlow framework. TensorQuant allows a transparent quantization simulation of existing DNN topologies during training and inference. TensorQuant supports generic quantization methods and allows experimental evaluation of the impact of the quantization on single layers as well as on the full topology. In a first series of experiments with TensorQuant, we show an analysis of fix-point quantizations of popular CNN topologies.
PDF Abstract

 ImageNet
ImageNet
 MNIST
MNIST
