Text2Cohort: Facilitating Intuitive Access to Biomedical Data with Natural Language Cohort Discovery
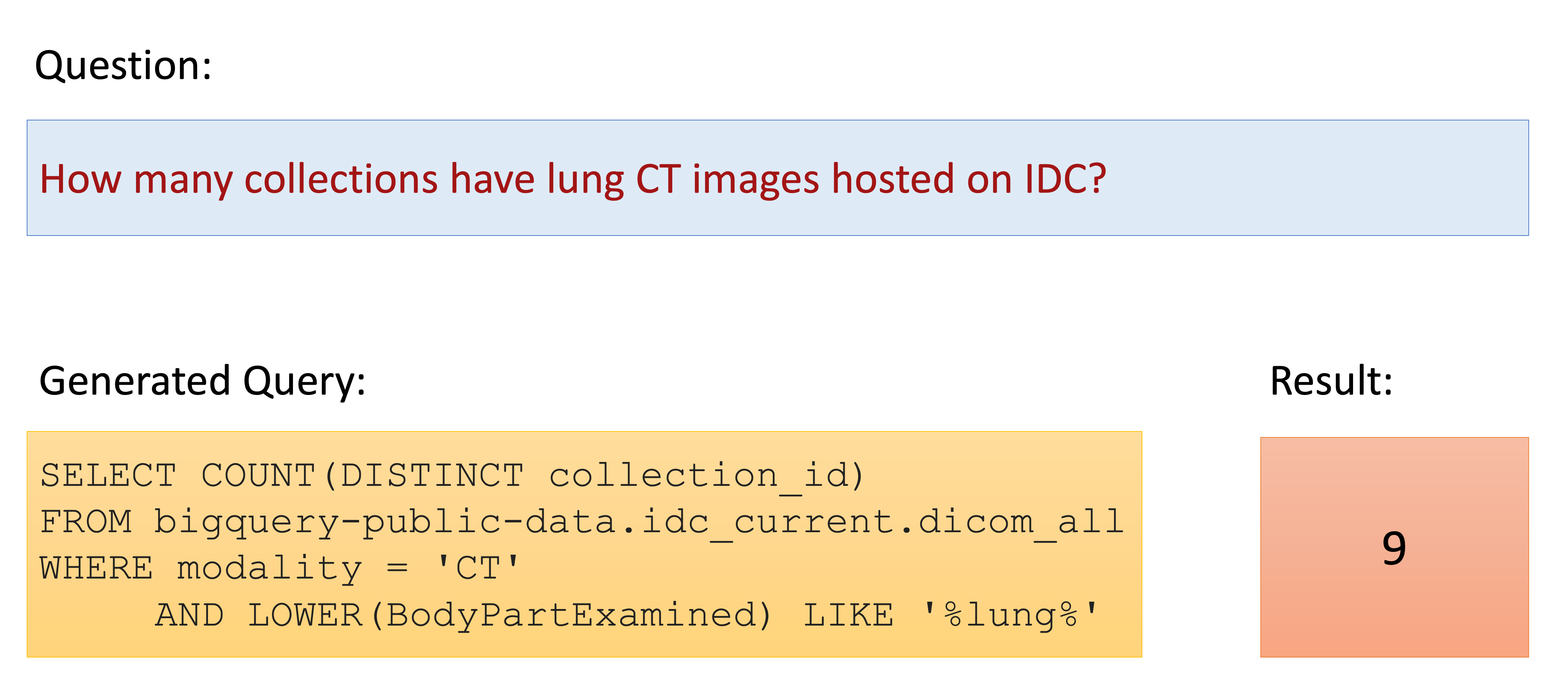
The Imaging Data Commons (IDC) is a cloud-based database that provides researchers with open access to cancer imaging data, with the goal of facilitating collaboration. However, cohort discovery within the IDC database has a significant technical learning curve. Recently, large language models (LLM) have demonstrated exceptional utility for natural language processing tasks. We developed Text2Cohort, a LLM-powered toolkit to facilitate user-friendly natural language cohort discovery in the IDC. Our method translates user input into IDC queries using grounding techniques and returns the query's response. We evaluate Text2Cohort on 50 natural language inputs, from information extraction to cohort discovery. Our toolkit successfully generated responses with an 88% accuracy and 0.94 F1 score. We demonstrate that Text2Cohort can enable researchers to discover and curate cohorts on IDC with high levels of accuracy using natural language in a more intuitive and user-friendly way.
PDF Abstract


