Transformers are Multi-State RNNs
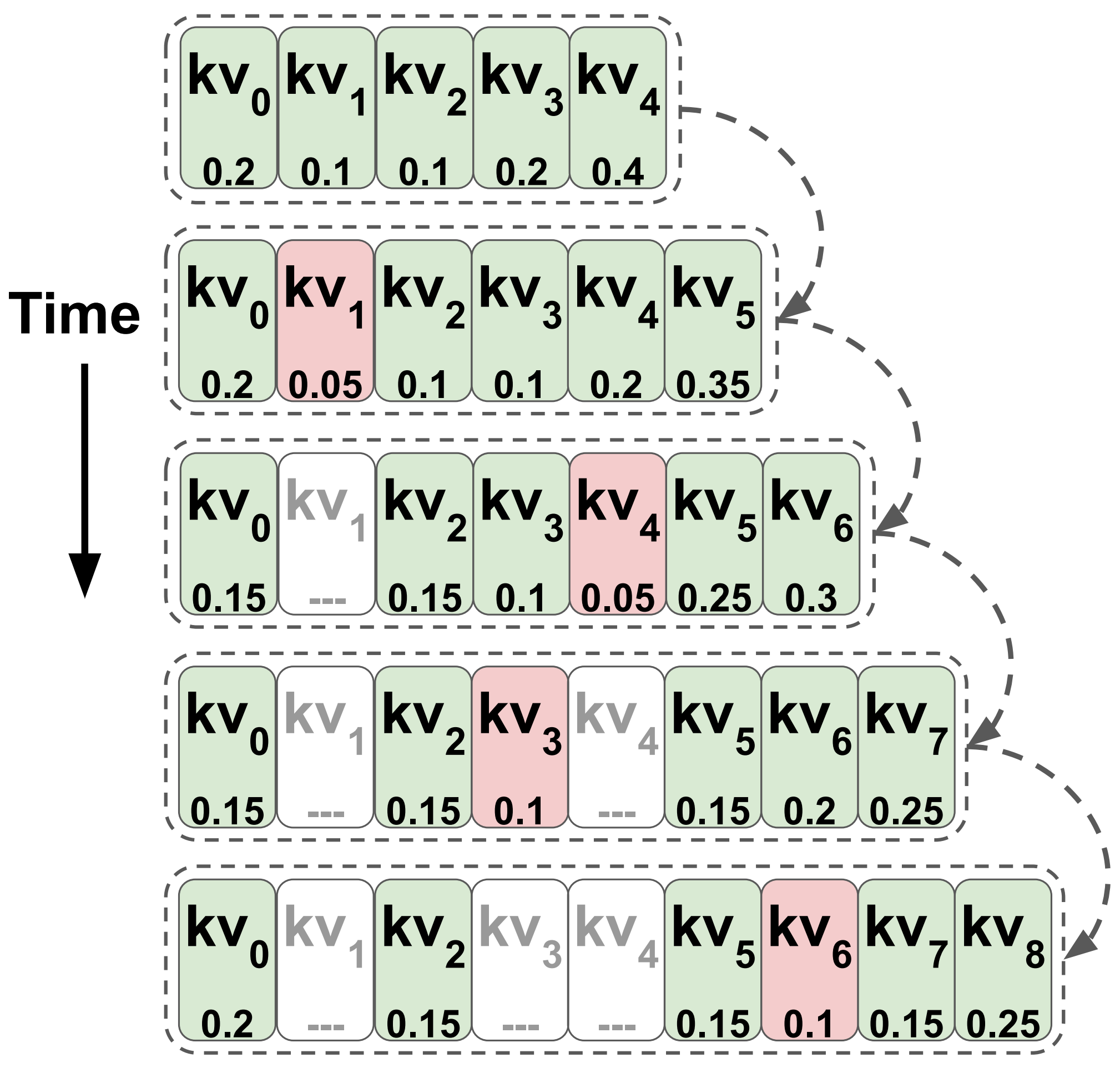
Transformers are considered conceptually different compared to the previous generation of state-of-the-art NLP models - recurrent neural networks (RNNs). In this work, we demonstrate that decoder-only transformers can in fact be conceptualized as infinite multi-state RNNs - an RNN variant with unlimited hidden state size. We further show that pretrained transformers can be converted into $\textit{finite}$ multi-state RNNs by fixing the size of their hidden state. We observe that several existing transformers cache compression techniques can be framed as such conversion policies, and introduce a novel policy, TOVA, which is simpler compared to these policies. Our experiments with several long range tasks indicate that TOVA outperforms all other baseline policies, while being nearly on par with the full (infinite) model, and using in some cases only $\frac{1}{8}$ of the original cache size. Our results indicate that transformer decoder LLMs often behave in practice as RNNs. They also lay out the option of mitigating one of their most painful computational bottlenecks - the size of their cache memory. We publicly release our code at https://github.com/schwartz-lab-NLP/TOVA.
PDF Abstract

