UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
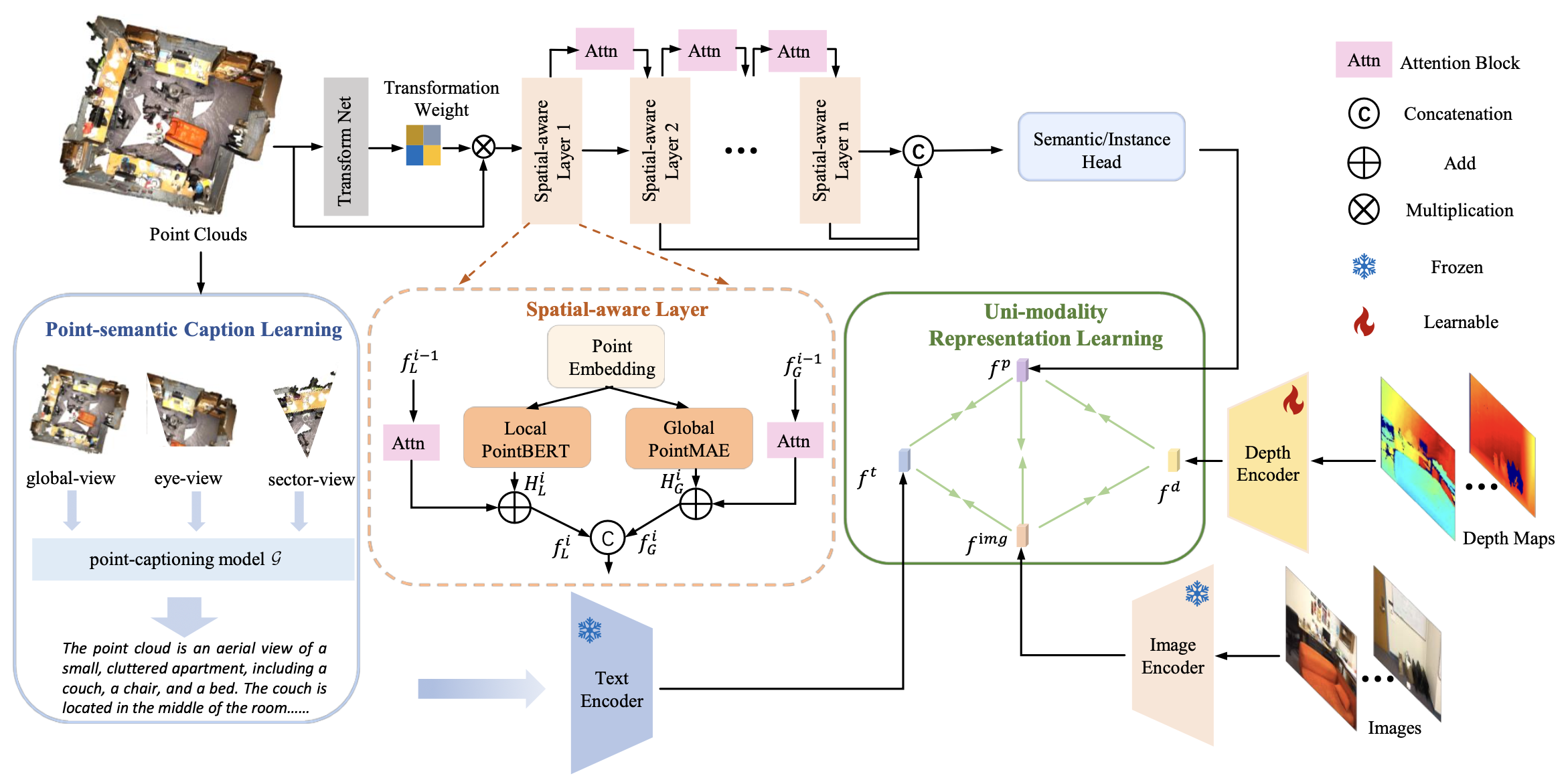
3D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
PDF Abstract


 nuScenes
nuScenes
 ScanNet
ScanNet
 S3DIS
S3DIS
