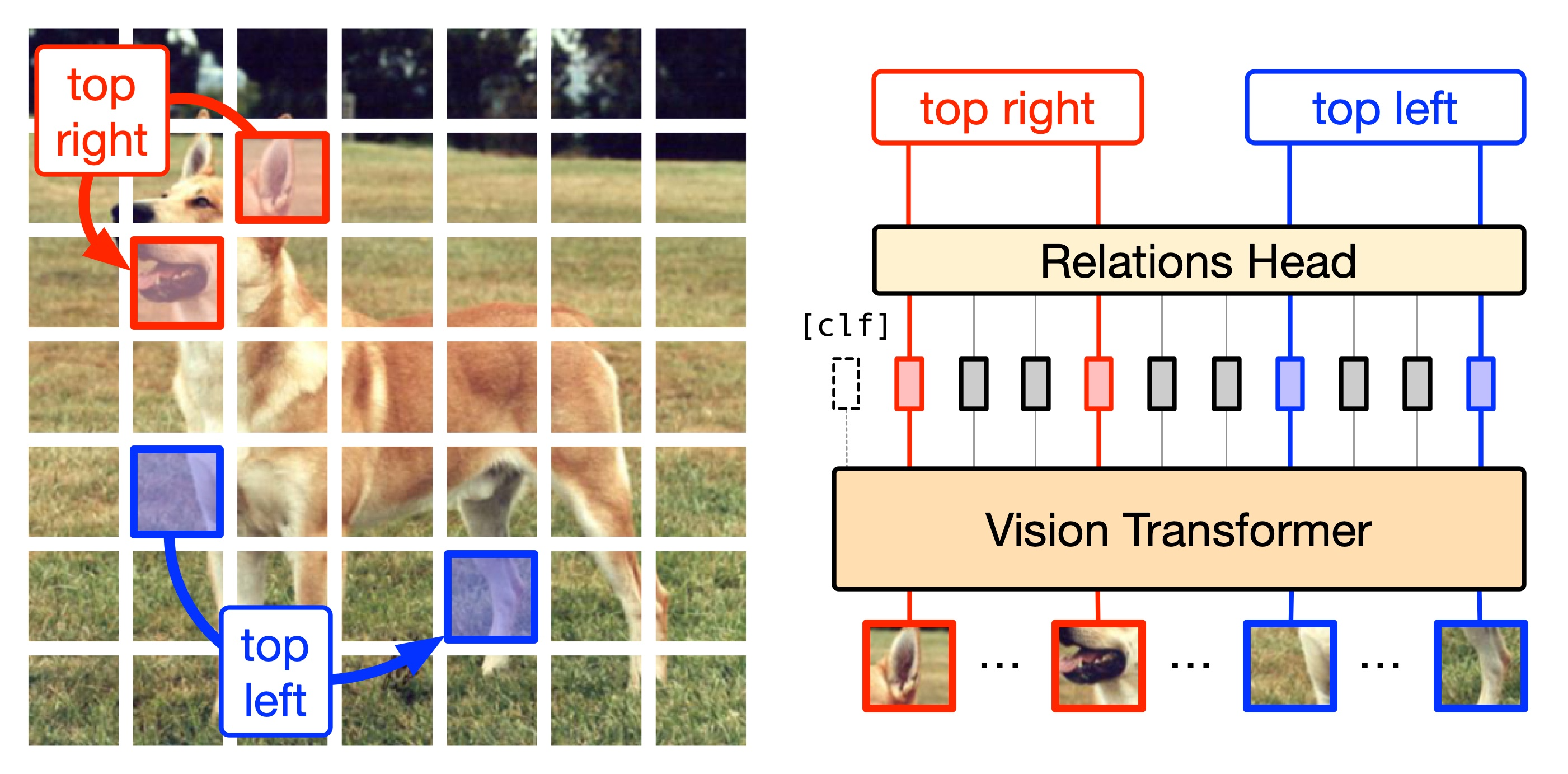
Where are my Neighbors? Exploiting Patches Relations in Self-Supervised Vision Transformer
Vision Transformers (ViTs) enabled the use of the transformer architecture on vision tasks showing impressive performances when trained on big datasets. However, on relatively small datasets, ViTs are less accurate given their lack of inductive bias. To this end, we propose a simple but still effective Self-Supervised Learning (SSL) strategy to train ViTs, that without any external annotation or external data, can significantly improve the results. Specifically, we define a set of SSL tasks based on relations of image patches that the model has to solve before or jointly the supervised task. Differently from ViT, our RelViT model optimizes all the output tokens of the transformer encoder that are related to the image patches, thus exploiting more training signals at each training step. We investigated our methods on several image benchmarks finding that RelViT improves the SSL state-of-the-art methods by a large margin, especially on small datasets. Code is available at: https://github.com/guglielmocamporese/relvit.
PDF Abstract


 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 SVHN
SVHN
 Tiny ImageNet
Tiny ImageNet
