With False Friends Like These, Who Can Notice Mistakes?
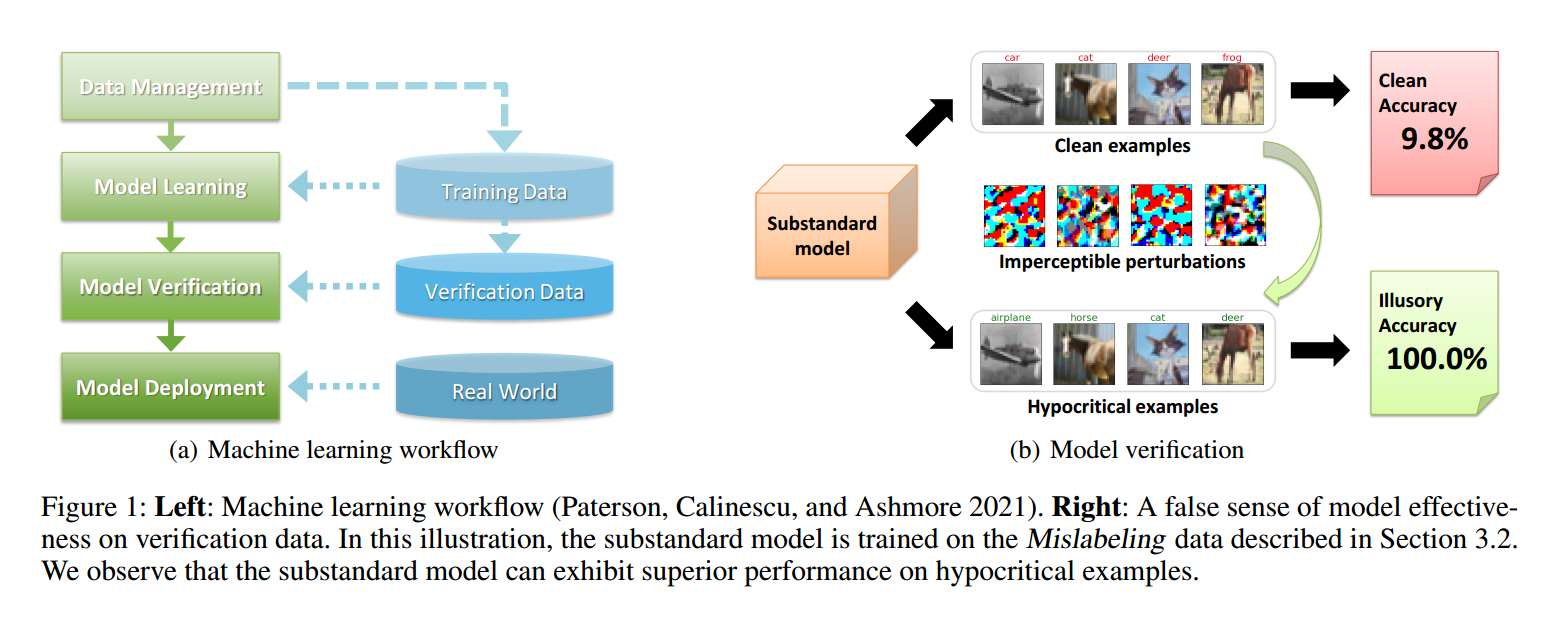
Adversarial examples crafted by an explicit adversary have attracted significant attention in machine learning. However, the security risk posed by a potential false friend has been largely overlooked. In this paper, we unveil the threat of hypocritical examples -- inputs that are originally misclassified yet perturbed by a false friend to force correct predictions. While such perturbed examples seem harmless, we point out for the first time that they could be maliciously used to conceal the mistakes of a substandard (i.e., not as good as required) model during an evaluation. Once a deployer trusts the hypocritical performance and applies the "well-performed" model in real-world applications, unexpected failures may happen even in benign environments. More seriously, this security risk seems to be pervasive: we find that many types of substandard models are vulnerable to hypocritical examples across multiple datasets. Furthermore, we provide the first attempt to characterize the threat with a metric called hypocritical risk and try to circumvent it via several countermeasures. Results demonstrate the effectiveness of the countermeasures, while the risk remains non-negligible even after adaptive robust training.
PDF Abstract
 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 SVHN
SVHN
