Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
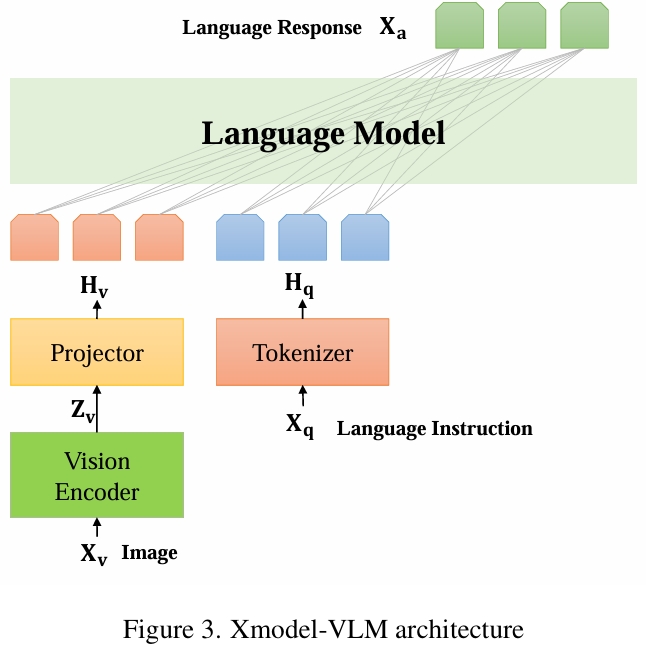
We introduce Xmodel-VLM, a cutting-edge multimodal vision language model. It is designed for efficient deployment on consumer GPU servers. Our work directly confronts a pivotal industry issue by grappling with the prohibitive service costs that hinder the broad adoption of large-scale multimodal systems. Through rigorous training, we have developed a 1B-scale language model from the ground up, employing the LLaVA paradigm for modal alignment. The result, which we call Xmodel-VLM, is a lightweight yet powerful multimodal vision language model. Extensive testing across numerous classic multimodal benchmarks has revealed that despite its smaller size and faster execution, Xmodel-VLM delivers performance comparable to that of larger models. Our model checkpoints and code are publicly available on GitHub at https://github.com/XiaoduoAILab/XmodelVLM.
PDF Abstract

 GQA
GQA
 VizWiz
VizWiz
 MM-Vet
MM-Vet
