Search Results for author:
Found 5 papers, 5 papers with code
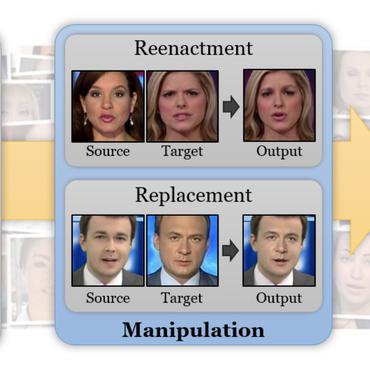
Unveiling the Truth: Exploring Human Gaze Patterns in Fake Images
Creating high-quality and realistic images is now possible thanks to the impressive advancements in image generation.

Trends, Applications, and Challenges in Human Attention Modelling
Human attention modelling has proven, in recent years, to be particularly useful not only for understanding the cognitive processes underlying visual exploration, but also for providing support to artificial intelligence models that aim to solve problems in various domains, including image and video processing, vision-and-language applications, and language modelling.

OpenFashionCLIP: Vision-and-Language Contrastive Learning with Open-Source Fashion Data
The inexorable growth of online shopping and e-commerce demands scalable and robust machine learning-based solutions to accommodate customer requirements.


LaDI-VTON: Latent Diffusion Textual-Inversion Enhanced Virtual Try-On
In this context, image-based virtual try-on, which consists in generating a novel image of a target model wearing a given in-shop garment, has yet to capitalize on the potential of these powerful generative solutions.
Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing
Given the lack of existing datasets suitable for the task, we also extend two existing fashion datasets, namely Dress Code and VITON-HD, with multimodal annotations collected in a semi-automatic manner.
